

По независимым оценкам, от 35 до 50% всего веб-трафика генерируют боты. Большинство владельцев сайтов первым делом открывают robots.txt и пишут там Disallow: / для подозрительных User-agent — и считают, что защита готова. Это опасное заблуждение: вредоносный бот прочитает ваш robots.txt, поймёт, что именно вы там прячете, и всё равно зайдёт.
Мы в BotHunt ежедневно обрабатываем более 50 млн запросов от сайтов клиентов и видим одну и ту же картину: парсеры, скрейперы и поведенческие боты не знают слова «нельзя». В этой статье разберём, как на самом деле работает robots.txt защита от ботов, какие краулеры его соблюдают, а какие — нет, и что делать вместо наивной надежды на этот файл.
Что такое robots.txt и как он работает
robots.txt — текстовый файл в корне сайта, описывающий правила обхода для краулеров (crawler). Протокол Robots Exclusion Protocol (REP) разработан в 1994 году Мартейном Костером и с тех пор не претерпел принципиальных изменений. Главное, что нужно знать о его природе: это не является стандартом безопасности — это лишь джентльменское соглашение. Технически любой бот может прочитать файл и просто проигнорировать его содержимое.
В 2022 году IETF (Internet Engineering Task Force) наконец опубликовал RFC 9309 — официальный стандарт протокола. Это повысило «юридический» вес файла, но не изменило техническую реальность: соблюдение robots.txt по-прежнему остаётся добровольным. Поисковые системы соблюдают его из-за договорённостей с индустрией и риска репутационных потерь. Вредоносным ботам такие соображения безразличны.
Базовый синтаксис файла:
User-agent: *
Disallow: /admin/
Allow: /
Crawl-delay: 1
User-agent: Googlebot
Disallow: /private/
Sitemap: https://example.ru/sitemap.xmlДиректива User-agent указывает, для какого робота действует правило. Звёздочка * означает «все боты». Disallow запрещает обход раздела, Allow явно разрешает (имеет приоритет над Disallow). Crawl-delay задаёт паузу между запросами: Яндексбот соблюдает, Googlebot — официально игнорирует.
robots.txt защита от ботов: кого остановит, а кого нет
Ключевое, что нужно понять: robots.txt соблюдают только боты, которым выгодно его соблюдать. Поисковые краулеры дорожат репутацией — нарушение правил грозит им блокировкой. Вредоносным ботам терять нечего.
Бот / краулер | Категория | Соблюдает robots.txt | Комментарий |
|---|---|---|---|
Googlebot | Поисковик | ✅ Да | Строго соблюдает, Crawl-delay игнорирует |
YandexBot | Поисковик | ✅ Да | Соблюдает, в т.ч. Crawl-delay |
Bingbot | Поисковик | ✅ Да | Соблюдает |
AhrefsBot | SEO-краулер | ⚠️ Частично | Заявляет о соблюдении, жалобы есть |
SemrushBot | SEO-краулер | ⚠️ Частично | Заявляет о соблюдении |
GPTBot (OpenAI) | AI-краулер | ✅ Да | OpenAI декларирует соблюдение |
ClaudeBot (Anthropic) | AI-краулер | ✅ Да | Anthropic соблюдает |
Bytespider (ByteDance/TikTok) | AI/Контент | ⚠️ Спорно | Агрессивный краулинг, много жалоб |
Парсеры (Python Requests, curl) | Скрейпер | ❌ Нет | Не читают robots.txt по умолчанию |
Поведенческие боты (ZennoPoster, BAS) | Накрутка ПФ | ❌ Нет | Имитируют браузер, robots.txt не парсят |
Спам-боты форм | Спам | ❌ Нет | Целенаправленно игнорируют |
Брутфорс-боты | Взлом | ❌ Нет | robots.txt не читают никогда |
Вывод очевиден: robots.txt работает только с добросовестными краулерами. Против реальных угроз — парсеров, накрутки поведенческих факторов, брутфорса, спама — он бесполезен. По данным BotHunt, более 73% вредоносного трафика поступает от ботов, которые вообще не читают robots.txt при инициализации сессии.
5 главных мифов о robots.txt как инструменте защиты
«Disallow: / закроет весь сайт от ботов» — только от добросовестных краулеров. Злоумышленник просто прочитает файл и узнает, что именно вы скрываете. Хуже того: если написать
Disallow: /для всех, вы потеряете индексацию в поисковиках. Вредоносный бот при этом зайдёт всё равно.«Запрет в robots.txt скрывает страницы от индексации» — нет. Google может индексировать URL даже при Disallow, если на него есть внешние ссылки — страница попадёт в индекс без содержимого. Для полного скрытия используйте
noindexв мета-теге или заголовке X-Robots-Tag.«Написал Disallow для вредоносного бота — и он больше не придёт» — парсеры и боты постоянно меняют User-agent. Завтра тот же бот придёт под именем Mozilla/5.0, Googlebot или случайной строкой. Блокировка по User-agent через robots.txt работает только против ботов, которые честно представляются.
«robots.txt защищает от DDoS и брутфорса» — нет. Боты, атакующие /wp-login.php или /admin/, не смотрят на robots.txt. Они ищут уязвимости, а не следуют правилам вежливости.
«Это юридический инструмент защиты от парсинга» — спорно. В российской судебной практике факт явного запрета в robots.txt иногда учитывается как свидетельство умысла нарушителя, но не является самостоятельным основанием для иска. Основные инструменты защиты — авторское право, условия использования сайта и технические меры.
BotHunt блокирует вредоносные боты до того, как они прочитают robots.txt — на уровне поведенческого анализа каждого запроса. Попробовать бесплатно →
Что robots.txt реально умеет: полезные директивы
Несмотря на мифы, robots.txt — рабочий инструмент для управления добросовестными краулерами, а их у вас может быть немало: Googlebot, YandexBot, Bingbot, различные SEO-аудиторы, AI-краулеры. Для этой аудитории файл работает отлично. Вот что он реально умеет:
Управляет нагрузкой от Яндекса и Google. Директива
Crawl-delayснижает частоту запросов. Яндекс соблюдает значения 1–3 секунды — актуально для высоконагруженных сайтов с дорогим бэкендом.Закрывает технические разделы от индексации. /wp-admin/, /checkout/, /cart/, /private/ — страницы, которые не должны попасть в поиск.
Указывает Sitemap. Директива
Sitemap:ускоряет нахождение XML-карты поисковиками и ускоряет индексацию новых страниц.Блокирует AI-краулеры, соблюдающие протокол. GPTBot, ClaudeBot, PerplexityBot, Google-Extended — все заявляют о соблюдении robots.txt.
Экономит crawl budget. Закрытие страниц с параметрами (?sort=, ?filter=) экономит бюджет сканирования для важных URL.

Honeypot-страница в robots.txt: как обнаружить вредоносного бота
Один из нестандартных способов использования robots.txt — ловушка (honeypot). Вы создаёте секретную страницу (например, /trap-bot-page/), добавляете её в robots.txt как Disallow, и ждёте реакции.
Добросовестный краулер прочитает запрет и не зайдёт. Если на honeypot приходят запросы — это либо вредоносный бот, либо краулер, сознательно игнорирующий правила. IP-адреса таких ботов можно сразу блокировать на уровне Nginx или передавать в BotHunt для анализа.
# Ловушки для вредоносных ботов
User-agent: *
Disallow: /trap-bot-page/
Disallow: /honeypot-admin/
Disallow: /decoy-data/
# Реальные технические разделы
Disallow: /wp-admin/
Disallow: /checkout/Важно: honeypot-страница должна быть реальной (возвращать 200 OK), но без ссылок на неё из обычного контента сайта. Заходить туда может только тот, кто прочитал robots.txt и сознательно нарушил правила. Это даёт вам «чистый» список вредоносных IP без ложных срабатываний.
Технику honeypot можно комбинировать с инструментами вроде BotHunt: когда IP заходит на ловушечную страницу, система автоматически повышает ему risk-score и начинает более внимательно анализировать все последующие запросы с этого адреса и связанных с ним устройств.
Актуальный список AI-краулеров 2025–2026: кого блокировать
С 2022 года количество AI-краулеров резко выросло. По данным Cloudflare, к середине 2025 года более 40% сайтов из топ-10 000 уже имеют явные блокировки хотя бы одного AI-агента. Вот актуальный список для robots.txt защиты от ботов:
Краулер | Компания | User-Agent для robots.txt | Соблюдает |
|---|---|---|---|
GPTBot | OpenAI |
| ✅ Да |
ClaudeBot | Anthropic |
| ✅ Да |
anthropic-ai | Anthropic |
| ✅ Да |
PerplexityBot | Perplexity AI |
| ✅ Да |
Google-Extended |
| ✅ Да | |
Bytespider | ByteDance / TikTok |
| ⚠️ Спорно |
CCBot | Common Crawl |
| ✅ Да |
Meta-ExternalAgent | Meta |
| ✅ Да |
OAI-SearchBot | OpenAI Search |
| ✅ Да |
Подробнее о том, как работают AI-краулеры и как их блокировать без потери трафика, читайте в статье «Скрейпинг AI-ботами: как заблокировать GPTBot и ClaudeBot».
robots.txt не остановит парсер — но BotHunt остановит. Защита работает в реальном времени без влияния на SEO. Подключить за 5 минут →
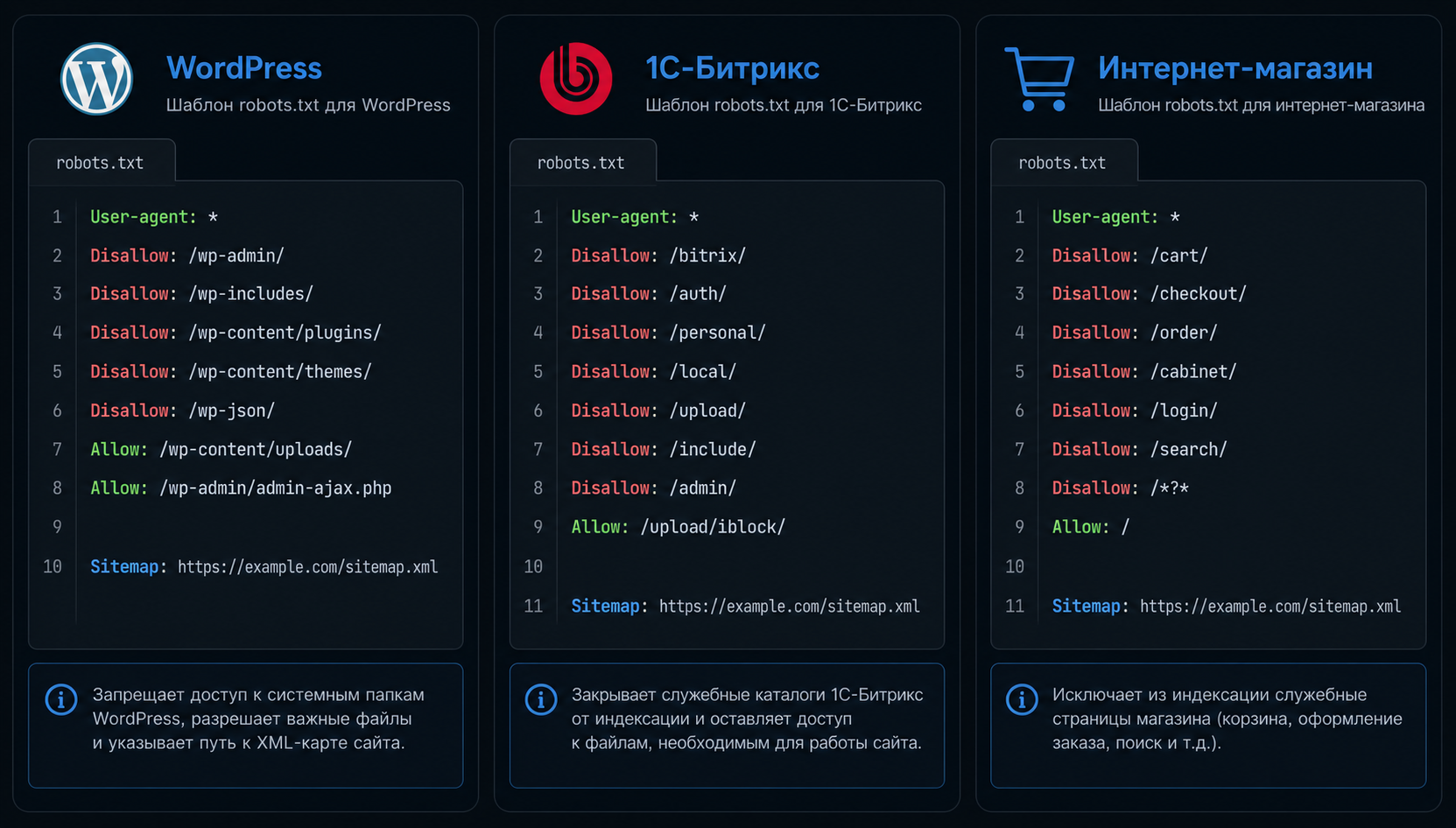
Готовые шаблоны robots.txt для популярных CMS
Вот рабочие шаблоны для трёх самых популярных платформ в Рунете. Они закрывают технические разделы от поисковиков и опционально блокируют AI-краулеров.
WordPress
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Disallow: /?s=
Disallow: /cart/
Disallow: /checkout/
Disallow: /my-account/
Allow: /wp-admin/admin-ajax.php
# Блокировка AI-краулеров (опционально)
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Bytespider
Disallow: /
Sitemap: https://yoursite.ru/sitemap.xml1С-Битрикс
User-agent: *
Disallow: /bitrix/
Disallow: /personal/
Disallow: /auth/
Disallow: /basket/
Disallow: /order/
Disallow: /search/
Disallow: /?s=
Disallow: /*?sort=
Disallow: /*?filter=
Disallow: /*?SECTION_ID=
Allow: /bitrix/js/
Allow: /bitrix/css/
Crawl-delay: 1
Sitemap: https://yoursite.ru/sitemap.xmlИнтернет-магазин (универсальный)
User-agent: *
Disallow: /cart/
Disallow: /checkout/
Disallow: /order/
Disallow: /compare/
Disallow: /wishlist/
Disallow: /*?utm_
Disallow: /*?ref=
Disallow: /*?sort=
Disallow: /*?filter=
Disallow: /*?page=
Disallow: /*&
Crawl-delay: 1
Sitemap: https://yoursite.ru/sitemap.xmlПравило для интернет-магазина: закрывайте URL с параметрами сортировки и фильтрации (?sort=, ?filter=, ?page=). Иначе поисковик обходит тысячи дублей страниц, тратя crawl budget (бюджет сканирования) на бесполезные варианты вместо приоритетных товарных страниц.
Чем дополнить robots.txt для реальной защиты от ботов
Для защиты от реальных угроз robots.txt нужно дополнять техническими инструментами. Вот сравнение подходов по ключевым параметрам:
Метод | От чего защищает | Сложность внедрения | Ограничения |
|---|---|---|---|
robots.txt | Добросовестные краулеры | Низкая | Только добровольное соблюдение |
Rate limiting (Nginx/Apache) | Массовые запросы, парсеры | Средняя | Не видит поведение, только частоту |
IP-блокировка | Известные вредоносные IP | Низкая | Боты меняют IP через прокси |
WAF (ModSecurity, Nginx+) | SQL-инъекции, XSS, сигнатуры | Высокая | Не видит поведенческих ботов |
Поведенческая аналитика (BotHunt) | Парсеры, накрутка ПФ, брутфорс, спам | Низкая (1 строка кода) | Нужен трафик для накопления сигналов |
Browser fingerprinting | Headless-браузеры, автоматизация | Высокая | Продвинутые боты обходят |
robots.txt управляет добросовестным трафиком. Для всего остального нужен отдельный уровень защиты. Оба инструмента не конкурируют — они дополняют друг друга.
О том, как полноценно закрыть сайт от парсеров на техническом уровне, читайте в материале «Как обнаружить парсер на своём сайте: 7 способов» и в пилларе «Защита сайта от парсеров: 15 рабочих методов».
robots.txt и crawl budget: как не навредить SEO
Одно из важнейших практических применений robots.txt — управление crawl budget (бюджетом сканирования). Яндекс и Google выделяют каждому сайту определённое количество запросов в единицу времени. Если краулер тратит их на технические страницы, дубли и параметрические URL — приоритетные страницы сканируются реже.
Что стоит закрыть в robots.txt для экономии crawl budget:
URL с параметрами:
/*?sort=, /*?filter=, /*?utm_— каждый уникальный набор параметров Яндекс воспринимает как отдельную страницу.Страницы пагинации при наличии rel=prev/next или canonical:
/*?page=.Дубли технических разделов: корзина, сравнения, избранное — они не несут SEO-ценности.
Страницы поиска по сайту:
/?s=, /search/— Яндекс их индексирует плохо и они занимают ресурс.
На крупных интернет-магазинах (от 50 000 SKU) правильная настройка robots.txt ускоряет переобход актуальных страниц в 2–3 раза. Новые поступления и изменения цен попадают в индекс быстрее — это прямое SEO-преимущество.
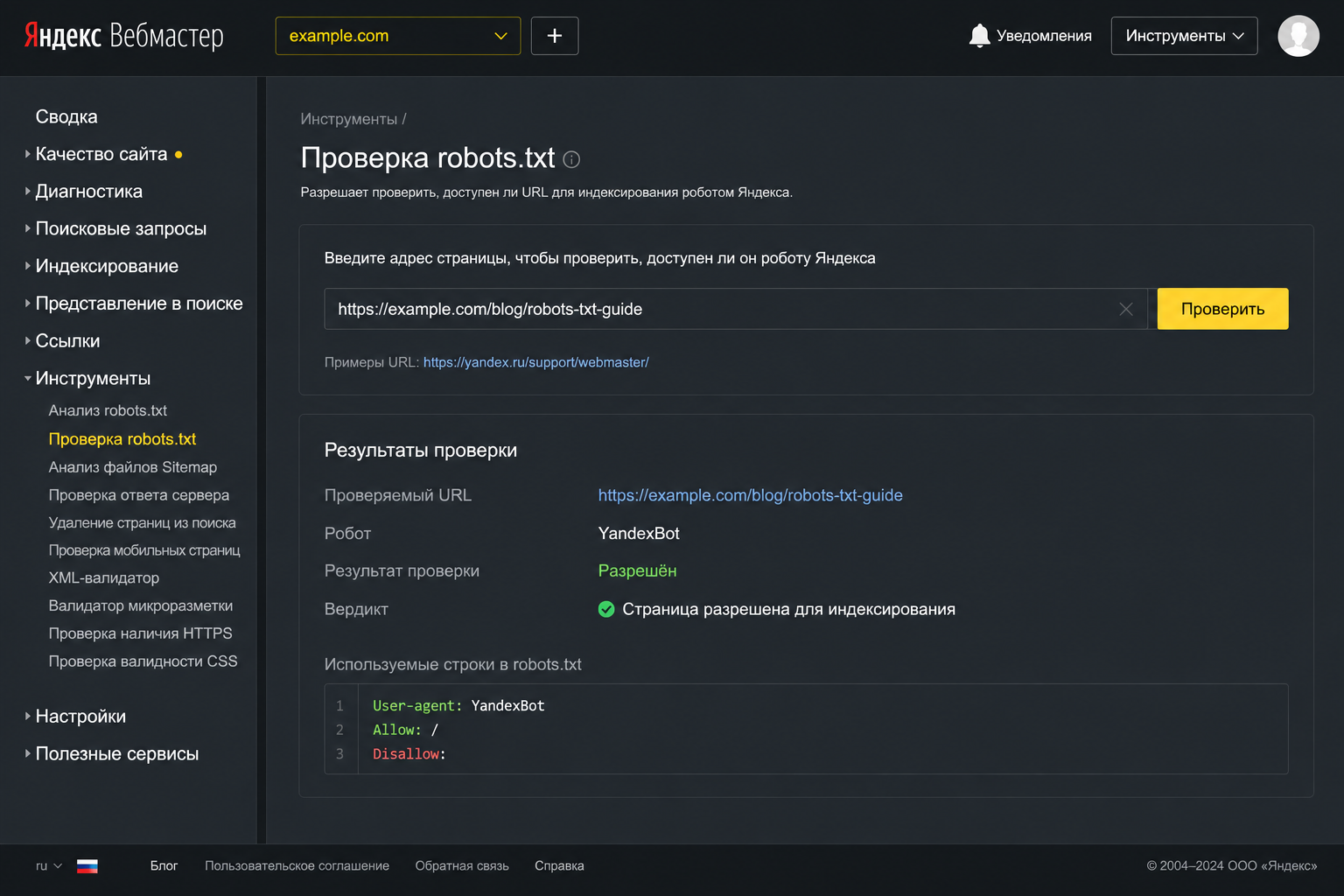
Как проверить robots.txt на ошибки
Ошибки в robots.txt могут случайно закрыть важные страницы от индексации или открыть лишнее. Особенно опасны ошибки после миграции CMS или смены структуры URL — поисковики могут потерять сотни страниц. Проверяйте файл после каждого изменения:
Яндекс Вебмастер → Инструменты → Проверка robots.txt. Показывает, как Яндексбот интерпретирует директивы. Позволяет протестировать любой URL.
Google Search Console → Инструмент проверки URL. Показывает, заблокирован ли URL для Googlebot в robots.txt или meta-тегах.
Robots.txt Tester в Google Search Console. Проверяет конкретные URL против правил вашего robots.txt прямо в интерфейсе GSC.
Официальный RFC: спецификация Robots Exclusion Protocol доступна на robotstxt.org — авторитетный источник для спорных случаев.
Особое внимание обращайте на wildcard-паттерны (* и $): синтаксис Google и Яндекса немного отличается. Google поддерживает * для обозначения любой последовательности символов и $ для конца URL. Яндекс поддерживает * аналогично. Лучше тестировать конкретные URL в инструментах обоих поисковиков, а не полагаться на интуицию.
Также рекомендуем периодически проверять robots.txt после обновления CMS или плагинов — некоторые из них перезаписывают файл автоматически, добавляя свои правила.
14 дней бесплатно — проверьте, сколько ботов обходит ваш robots.txt прямо сейчас. Подключить BotHunt →
Часто задаваемые вопросы
Нужно ли закрывать всё в robots.txt, чтобы защититься от ботов?
Нет. Это не поможет против вредоносных ботов, но может навредить SEO — поисковики не проиндексируют нужные страницы. Закрывайте только технические разделы (admin, cart, checkout), которые не должны попадать в выдачу.
Могут ли вредоносные боты использовать мой robots.txt против меня?
Да. Файл публичен — его читают все. Если написать Disallow: /secret-pricing/, вы фактически указали, где лежат чувствительные данные. Для реально конфиденциальных разделов используйте авторизацию и блокировки на уровне сервера — не раскрывайте их пути в robots.txt.
Что такое Crawl-delay и стоит ли его использовать?
Crawl-delay задаёт паузу между запросами краулера. Яндексбот соблюдает значения 1–3 секунды — это полезно для снижения нагрузки на сервер. Google официально игнорирует Crawl-delay в robots.txt. Для управления скоростью Google используйте Google Search Console → Настройки → Скорость сканирования.
Стоит ли блокировать GPTBot и другие AI-краулеры?
Зависит от стратегии. Если вы продаёте уникальный контент — блокировка защищает данные от использования в обучении моделей. Если хотите, чтобы AI-сервисы (ChatGPT, Claude) ссылались на ваш сайт как источник — блокировать не стоит. В 2025–2026 году AI-цитируемость становится новым SEO-сигналом для части аудитории.
Как проверить, что бот действительно является Googlebot, а не маскируется?
Через обратный DNS-поиск (reverse DNS lookup) по IP-адресу запроса. Настоящий Googlebot имеет hostname вида crawl-xxx-xxx-xxx-xxx.googlebot.com. Яндекс-боты приходят с *.yandex.ru или *.yandex.net. Любой другой IP под именем Googlebot — самозванец. Подробнее: официальная документация Google Developers по верификации Googlebot.
Что лучше: robots.txt или .htaccess для блокировки ботов?
Для разных задач. robots.txt управляет индексацией добросовестными краулерами. .htaccess (или конфиг Nginx) блокирует на уровне веб-сервера — это технический запрет, который нельзя обойти через игнорирование файла. .htaccess работает для всех запросов; robots.txt — только для ботов, которые его читают и хотят соблюдать.
Как robots.txt влияет на позиции в Яндексе?
Напрямую — только через управление сканированием. Если закрыть важные страницы от YandexBot, они выпадут из индекса. Косвенно — правильно настроенный robots.txt сохраняет crawl budget на приоритетных страницах вместо технических дублей и параметрических URL, что ускоряет индексацию обновлений.


