

Парсер скачивает ваш контент молча. Он не оставляет заявку, не звонит в отдел продаж и в идеале старается выглядеть как обычный посетитель из Chrome. Поэтому большинство владельцев сайтов годами не догадываются, что их цены, описания товаров, статьи и база контактов утекают к конкурентам. Первый шаг к защите — научиться вовремя обнаружить парсер: прочитать следы, которые он оставляет в логах сервера, в аналитике и в поведении на странице.
Мы в BotHunt ежедневно анализируем десятки миллионов запросов и видим, что на сайтах e-commerce, медиа и агрегаторов доля автоматизированного трафика в среднем достигает 30–50%, а в пиковые периоды парсеры генерируют больше запросов, чем живые люди. В этой статье разберём 7 практических способов вычислить парсер — от готовых команд для разбора логов до поведенческого анализа и TLS-отпечатков. После прочтения вы сможете за полчаса проверить, парсят ли ваш сайт прямо сейчас.
Зачем и когда нужно обнаружить парсер на сайте
Парсинг сам по себе не всегда вредит: поисковые роботы Яндекса и Google тоже парсят сайт, и это полезно. Проблема начинается, когда контент тянут без спроса и используют против вас. Вот к чему это приводит:
Дубли контента. Спарсенные тексты появляются на чужих сайтах. Для Яндекса это сигнал неуникальности, и иногда первоисточник проседает в выдаче ниже копии.
Демпинг по ценам. Парсер мониторит ваш прайс несколько раз в день, и конкурент автоматически ставит цену на рубль ниже. Подробнее — в материале про защиту цен интернет-магазина от парсинга.
Нагрузка на сервер. Агрессивный парсер в сотни потоков ведёт себя как мелкий DDoS: растёт время ответа, хостинг присылает уведомления о превышении лимитов.
Утечка базы. Парсятся карточки специалистов, телефоны, e-mail — дальше это уходит в холодные обзвоны и спам-рассылки.
Чтобы понять масштаб и решить, как реагировать, парсер сначала нужно обнаружить и опознать. Ниже — 7 способов, от самого простого к самому глубокому. Их можно комбинировать: чем больше сигналов сошлось, тем выше уверенность.
Способ 1. Анализ логов веб-сервера
Логи доступа (access.log у Nginx, access_log у Apache) — главный и бесплатный источник правды. В них записан каждый запрос: IP, дата, метод, URL, код ответа, User-Agent. Парсер физически не может не оставить здесь след. Начните с поиска IP-адресов, которые сделали аномально много запросов.
Топ-20 самых активных IP за период:
awk '{print $1}' access.log | sort | uniq -c | sort -rn | head -20Топ-20 User-Agent — сразу видно curl, python и прочие непользовательские клиенты:
awk -F'"' '{print $6}' access.log | sort | uniq -c | sort -rn | head -20Что именно запрашивал конкретный подозрительный IP:
grep '203.0.113.45' access.log | awk '{print $7}' | sort | uniq -c | sort -rn | head -30О парсере говорят три характерных признака в логах. Первый — один IP с тысячами обращений за час, тогда как живой человек делает десятки. Второй — клиент тянет только HTML-страницы и игнорирует .css, .js, картинки и счётчики: браузер всегда подгружает статику, а парсеру она не нужна. Третий — последовательный обход по структуре (по карте сайта или пагинации подряд), которого у людей не бывает.
Для удобства поставьте GoAccess — он строит наглядный отчёт по логам прямо в терминале или в HTML. Глубокий разбор команд мы собрали в отдельной статье «Логи Nginx: как найти ботов за 10 минут».
Способ 2. User-Agent: сигнатуры парсеров
Простые парсеры даже не пытаются маскироваться и отправляют User-Agent библиотеки, которой написаны. Это самый быстрый способ обнаружить нетехничного нарушителя. Вот характерные строки и уровень угрозы:
User-Agent (фрагмент) | Инструмент | Что значит |
|---|---|---|
| Python requests | Скрипт без браузера, маскировки нет |
| Scrapy | Промышленный фреймворк парсинга |
| curl / wget | Ручной или примитивный сбор |
| Go net/http | Самописный парсер на Go, часто массовый |
| Java-клиент | Корпоративный скрейпер |
| Node.js | Парсер на JavaScript без браузера |
| Puppeteer / Playwright | Headless-браузер, маскировка слабая |
Важная оговорка: User-Agent подделывается одной строкой кода, поэтому продвинутый парсер представится свежим Chrome на Windows. Считайте этот способ первым ситом, а не финальным вердиктом. Отдельно проверяйте подделку поисковиков: бот, который называет себя Googlebot или YandexBot, обязан проходить обратный DNS-запрос на официальный домен — иначе это маскировка.
# проверяем, настоящий ли это Googlebot
host 66.249.66.1
# ответ должен быть *.googlebot.com / *.google.comСпособ 3. Аномалии в Яндекс Метрике и аналитике
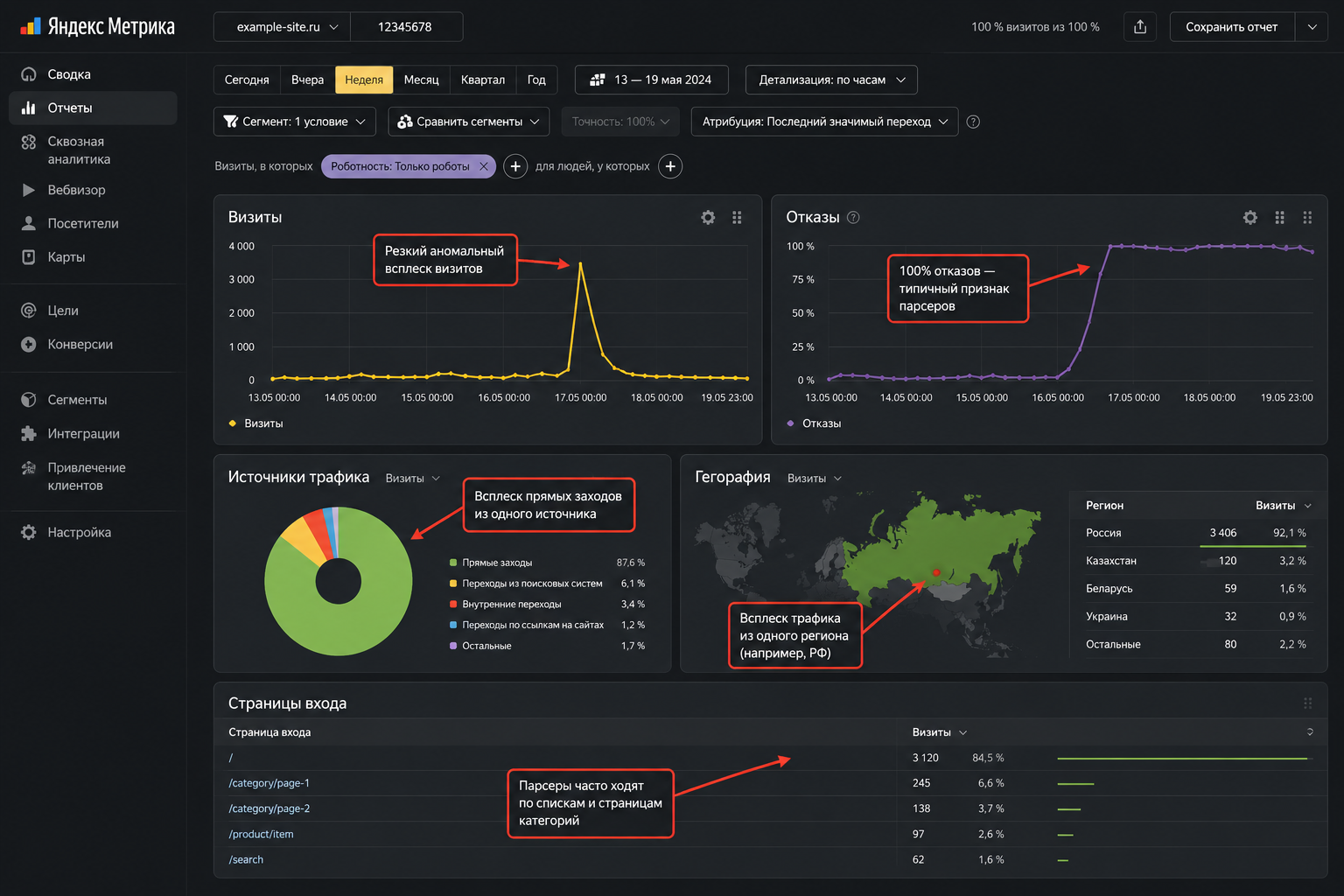
Если доступа к логам нет, многое видно прямо в Яндекс Метрике. В отчётах есть отдельный сегмент «Роботы», а аномалии выдают себя характерной картиной. Тревожные признаки:
Резкий всплеск визитов без единой конверсии и без роста заявок.
Показатель отказов под 100% при времени на сайте, близком к нулю.
Массовые «прямые заходы» (Direct) без источника — типичная подпись ботов.
Аномальная география: весь всплеск из одного города, дата-центра или одной страны.
Один и тот же браузер + версия ОС + разрешение экрана у тысяч «посетителей».
Включите в Метрике сегментацию по роботности и сравните «живой» и «роботный» трафик — подробный разбор есть в статье «10 признаков мусорного трафика в Яндекс Метрике». Принципы фильтрации роботов описаны в справке Яндекс Метрики.
Ключевая ловушка: большинство парсеров вообще не исполняют JavaScript, поэтому счётчик Метрики у них не срабатывает и в аналитику они не попадают. Чистая аналитика ещё не значит, что парсера нет, — она значит, что его надо искать в логах (способ 1).
BotHunt показывает долю ботов и парсеров в дашборде в реальном времени — без копания в логах вручную. Попробуйте бесплатно 14 дней. Подключить защиту →
Способ 4. Частота и скорость запросов
Поведение во времени выдаёт автоматизацию надёжнее, чем User-Agent. Живой человек просматривает 5–20 страниц за сессию, делает паузы в 5–60 секунд, отвлекается. Парсер ведёт себя иначе:
Высокая частота. Сотни и тысячи запросов с одного IP или подсети за минуты.
Машинная регулярность. Интервалы между запросами строго одинаковые (например, ровно 10,0 секунды — это троттлинг, попытка «прикинуться человеком»).
Линейный обход. Страницы идут строго по порядку:
?page=1,?page=2,?page=3— или ровно по карте сайта.Ночная активность. Пики в 3–5 утра по местному времени, когда реальная аудитория спит.
Сгруппируйте запросы по IP и посмотрите на распределение интервалов. Идеально ровные паузы или, наоборот, десятки запросов в секунду — это не человек. Именно частоту и регулярность в первую очередь оценивает rate limiting и поведенческие алгоритмы антибот-сервисов.
Способ 5. Honeypot-ловушки для парсеров
Honeypot («горшочек мёда») — это приманка, невидимая для человека, но заметная для программы, которая читает HTML. Парсер обходит все ссылки подряд и попадает в ловушку, а реальный посетитель её даже не видит. Любой заход на такой адрес — почти стопроцентный признак бота.
Как устроить ловушку:
Скрытая ссылка. Добавьте на страницу ссылку на
/do-not-follow-trap, спрятанную черезdisplay:noneили вынесенную за пределы экрана. Человек по ней не кликнет.Запрет в robots.txt. Пропишите этот URL в
Disallow. Добросовестные роботы (Яндекс, Google) его не тронут — туда полезут только нарушители, игнорирующие правила.Логирование и реакция. Любой заход на адрес-ловушку фиксируйте и помечайте IP как подозрительный — вплоть до автоматического бана.
Плюс honeypot — он ловит даже хорошо замаскированные парсеры, которые подделали User-Agent и притормозили скорость. Минус — он не поймает таргетированный парсер, который тянет только конкретные карточки товаров и не ходит по всем ссылкам.
Способ 6. Поведенческие признаки на странице
Самый надёжный способ обнаружить парсер — посмотреть, как «посетитель» ведёт себя внутри страницы. У бота нет рук и глаз, поэтому он выдаёт себя отсутствием человеческой моторики:
Нет движений мыши и нет траектории курсора (у человека это кривая, у бота — ничего или прямая линия).
Нет скролла и нет фокуса по полям — контент «прочитан» мгновенно.
Не загружаются шрифты, фоновые изображения, трекеры и сторонние скрипты.
navigator.webdriverвозвращаетtrue— прямой признак автоматизации Selenium/Puppeteer.Окно без фокуса, нулевое разрешение или стандартное 800×600 у headless-браузера.
Простой приём для самостоятельной проверки — JavaScript-челлендж: небольшой скрипт ставит cookie или скрытый маркер только при реальной отрисовке страницы. Запросы, приходящие без этого маркера, с высокой вероятностью идут от парсера, который тянет голый HTML. Глубже механика разобрана в статье «Как бот имитирует пользователя».

Поведенческий анализ движений мыши и тайминга кликов BotHunt выполняет за 4–12 мс на каждый запрос, с точностью 99,9%. Посмотреть, как это работает →
Способ 7. Технические отпечатки: TLS/JA3 и headless
Самые продвинутые методы работают ещё до того, как сервер отдал HTML. При установке HTTPS-соединения клиент отправляет TLS-пакет ClientHello, из которого считается отпечаток JA3/JA4. У python, curl и Go-клиентов он характерный и не совпадает с отпечатком настоящего Chrome. Если User-Agent говорит «я Chrome», а JA3 — «я python», то перед вами замаскированный парсер.
Дополнительные технические сигналы:
ASN и тип IP. Запросы из дата-центров (Hetzner, OVH, DigitalOcean, Selectel) подозрительнее, чем из домашних сетей провайдеров. Резидентные прокси сложнее, но и они палятся по репутации.
Headless-сигнатуры. Следы протокола CDP, отсутствие плагинов, нестандартный порядок HTTP-заголовков, рассинхрон между заявленной и реальной платформой.
Несовпадение слоёв. TLS говорит одно, User-Agent — другое, JavaScript-фингерпринт — третье. Любой рассинхрон между уровнями — красный флаг.
Вручную собрать и сопоставить эти сигналы тяжело — нужен слой, который видит TLS, заголовки и поведение одновременно. Это и делают антибот-сервисы. Отдельно стоит вопрос AI-ботов вроде GPTBot и ClaudeBot, которые массово парсят сайты для обучения нейросетей.
Сводная таблица: как обнаружить парсер 7 способами
Способы дополняют друг друга. Простые внедряются за час, глубокие ловят замаскированных нарушителей:
Способ | Что обнаруживает | Сложность | Ловит продвинутый парсер |
|---|---|---|---|
1. Логи сервера | Всплески запросов, обход без статики | Низкая | Частично |
2. User-Agent | Скрипты без маскировки | Низкая | Нет |
3. Аналитика и Метрика | Аномальные визиты с JS | Низкая | Частично |
4. Частота запросов | Регулярность, скорость, линейный обход | Средняя | Да |
5. Honeypot | Любой обходчик ссылок | Средняя | Да |
6. Поведение на странице | Отсутствие мыши, скролла, JS | Средняя | Да |
7. TLS/JA3 и headless | Маскировку под Chrome | Высокая | Да |
Что делать после того, как обнаружили парсер
Нашли парсер — не спешите рубить сплеча. Порядок действий, который снижает риск ложных блокировок:
Подтвердите, что это не поисковик. Прогоните IP через обратный DNS. Заблокировать настоящего YandexBot или Googlebot — значит выпасть из выдачи.
Оцените ущерб. Что именно тянут: цены, тексты, контакты? От этого зависит, бороться точечно или закрывать весь раздел.
Выберите реакцию. Варианты по нарастанию: rate limiting, блок по IP/ASN, капча на подозрительных, поведенческая защита без фрикшена для людей.
Не блокируйте вслепую. Жёсткие правила по IP легко обходятся сменой прокси и бьют по живым пользователям за NAT. Точнее работает анализ поведения и отпечатков.
Важно: robots.txt парсер не остановит — он лишь просит вести себя прилично, а нарушитель эту просьбу игнорирует. Почему это так, разбираем в статье «robots.txt для защиты от ботов: мифы и реальность». Полный набор методов защиты — в гайде «Как защитить сайт от парсеров: 15 методов».
Не хотите вручную разбирать логи и писать правила? BotHunt обнаруживает и блокирует парсеры автоматически — установка за 1 минуту, 14 дней бесплатно. Начать бесплатно →
Часто задаваемые вопросы
Можно ли точно обнаружить парсер на сайте?
По одному признаку — не всегда: грамотный парсер маскируется под браузер и притормаживает скорость. Но по совокупности сигналов (логи, частота, поведение, TLS-отпечаток) уверенность приближается к 100%. Чем больше способов из этой статьи сошлось на одном IP, тем выше вероятность, что это бот.
Как отличить парсер от Googlebot и YandexBot?
Прогоните IP через обратный DNS-запрос (host или nslookup). Настоящие поисковые роботы резолвятся на официальные домены (*.googlebot.com, *.yandex.ru) и работают из известных диапазонов. Если User-Agent говорит «YandexBot», а DNS показывает дата-центр в другой стране — это подделка.
Видно ли парсеров в Яндекс Метрике?
Чаще всего нет. Большинство парсеров не исполняют JavaScript, поэтому счётчик у них не срабатывает и в отчёты они не попадают. Метрика хорошо показывает ботов, которые имитируют визиты с браузером, но для поиска «тихих» парсеров нужны логи сервера.
Какие User-Agent у популярных парсеров?
Самые частые непользовательские сигнатуры: python-requests, Scrapy, curl, Wget, Go-http-client, Java, node-fetch и axios. Headless-браузеры могут отдавать HeadlessChrome. Но помните: User-Agent подделывается, поэтому это лишь первичный фильтр.
Сколько запросов с одного IP считать парсером?
Жёсткого порога нет — всё зависит от типа сайта. Ориентир: десятки и сотни запросов в минуту с одного IP либо строго равные интервалы между обращениями. Важнее не абсолютное число, а регулярность и отсутствие загрузки статики и JS.
Что делать, если парсер маскируется под Chrome?
User-Agent тут бесполезен — переходите к глубоким сигналам: TLS/JA3-отпечаток, поведение на странице (движения мыши, скролл), исполнение JavaScript и репутация IP/ASN. Несовпадение между заявленным браузером и реальным отпечатком выдаёт маскировку.
Можно ли обнаружить парсер без программиста?
Базовую диагностику реально провести самому: посмотреть аномалии в Яндекс Метрике и попросить хостинг прислать выгрузку логов. Для постоянного мониторинга и автоматической блокировки проще подключить антибот-сервис вроде BotHunt — он ставится одной строкой кода и показывает долю ботов в дашборде.


