

По нашим данным в BotHunt, у среднего регионального интернет-магазина с каталогом в 5–15 тыс. позиций до 18% всего входящего трафика — это парсеры цен. Они приходят от прямых конкурентов, маркетплейсов, агрегаторов и AI-ассистентов: за ночь снимают цены, утром те же данные уже работают в чужих ценовых стратегиях. Если вы держите розничную цену чуть выше рынка ради маржи — парсер видит это первым, и ваш покупатель уходит туда, где «купить дешевле на 137 ₽». Это не теория: такие сценарии мы фиксируем у клиентов еженедельно.
Защита от парсинга цен — задача не «один раз поставить и забыть», а постоянная гонка с инструментами автоматизации, которые за последние два года прыгнули далеко вперёд. ZennoPoster и BrowserAutomationStudio (BAS) умеют имитировать движения мыши, AI-агенты на базе LLM решают капчи быстрее людей, а резидентные прокси за 4 ₽ за IP делают примитивные блокировки бесполезными. В этой статье разобрали 11 методов защиты, которые реально работают в 2026 году, с честными плюсами и минусами каждого, юридическими рычагами и чек-листом внедрения за 7 дней.
Материал написан для владельцев и SEO/CTO интернет-магазинов на 1С-Битрикс, WordPress + WooCommerce, OpenCart, Tilda и кастомных платформах. Если у вас каталог от 500 SKU — статья окупится за один разговор с подрядчиком.
Зачем конкуренты собирают ваши цены автоматически
Парсинг цен — базовая операция в e-commerce аналитике, и на каждый интернет-магазин в среднем приходится от 4 до 30 регулярных «потребителей» этих данных. Их можно разделить на категории, и понимание мотивации помогает строить защиту целенаправленно, а не «всех подряд блокируем».
Прямые конкуренты — пересчитывают цены раз в час, чтобы держать минимум по топовым SKU.
Маркетплейсы — Wildberries, Ozon, Яндекс Маркет проверяют, не нарушает ли продавец рекомендованную розничную цену и не дешевле ли его собственный сайт.
Агрегаторы и сравнивашки — Я.Маркет, Sravni.ru, ALL RIVAL парсят сотни магазинов, чтобы строить ценовые сравнения.
Сервисы динамического ценообразования — uXprice, Pricer24, Z-PRICE, MarketParser — продают вашим конкурентам инструмент, который автоматически переоценивает их каталог по вашему.
AI-ассистенты — отвечают на вопрос «где купить N дешевле» и в фоне обходят сайты в реальном времени.
Спекулянты — собирают цены, чтобы выкупить дефицитные позиции и перепродать.
Самые массовые из этих игроков — сервисы динамического ценообразования. Их парсер ходит к вам не раз в неделю, а каждые 15–60 минут по топ-100 SKU. Если у вас в категории «iPhone 15 Pro 256» две сотни оферов на маркетплейсе — каждые 30 минут сервис обходит все товарные страницы, агрегирует цены, потом выдаёт владельцу красивый дашборд: «вы дороже рынка на 4,2%, скиньте 3 200 ₽». Алгоритм меняет цену конкурента автоматически — вы даже не успеваете отреагировать.
С AI-ботами в 2026 ситуация ещё острее. По нашим телеметрическим данным, доля визитов от GPTBot, ClaudeBot, PerplexityBot и подобных в e-commerce выросла с 0,4% в начале 2024 года до 6,1% к маю 2026. Они не просто индексируют — они читают цены и подают их пользователям ChatGPT и Perplexity напрямую, обходя ваш сайт. Подробно эту тему разбираем в статье «Защита от AI-ботов GPTBot и ClaudeBot».
Сколько денег теряет интернет-магазин из-за парсинга цен
Прямой убыток от парсинга цен непрозрачен — он растворён в нескольких метриках, и владелец редко связывает их с автоматическим сбором данных. Мы в BotHunt разобрали 12 случаев, где после подключения защиты от парсеров клиенты увидели изменения, и собрали типовую картину потерь.
Перерасход на инфраструктуру
Парсер вызывает ваш каталог в десятки раз чаще, чем живой пользователь. На клиентском магазине бытовой техники с 28 000 SKU мы зафиксировали, что 73% запросов к карточкам товаров приходились на ботов. После отсечки парсеров RPS на сервере упал в 3,4 раза, и клиент отказался от плана VPS за 24 000 ₽/мес в пользу 7 000 ₽/мес. Прямая экономия — 17 000 ₽ в месяц только на хостинге.
Снижение маржи из-за демпинга
Сценарий: ваш конкурент — крупная сеть с прайсингом по матрице. Их алгоритм держит цену «−1 ₽ к минимальной по выдаче». Ваша цена попадает к ним через парсер за 20 минут, и они автоматически опускают свою. Покупатель сравнивает в Я.Маркете, видит их дешевле — уходит. Закрыв парсинг для этого конкурента, вы возвращаете контроль над сценарием: теперь они либо парсят с лагом в часы (и вы успеваете манёвр), либо ориентируются на другого игрока.
Падение позиций в Яндексе и Google
Парсеры с резидентных прокси неизбирательны: они генерируют отказы, короткие сессии, выходы за 1–2 секунды. Эти сигналы попадают в Метрику, искажают поведенческие факторы и косвенно роняют позиции (подробно — в статье «8 признаков поведенческих ботов на сайте»). Плюс кратковременные пиковые нагрузки от парсера могут уронить TTFB и попасть в санкции Core Web Vitals.
Утечка стратегических данных
Помимо цен парсер забирает ваш ассортимент, наличие, акции, способы доставки, скидки клиентам категории «оптовик». Эти данные используются для копирования вашей коммерческой модели — вплоть до того, что конкурент в течение недели открывает аналогичные страницы с теми же УТП, перенесёнными почти дословно.
Хотите проверить, кто парсит ваш интернет-магазин прямо сейчас? Подключите BotHunt бесплатно на 14 дней — установка занимает 1 минуту. Запустить защиту →
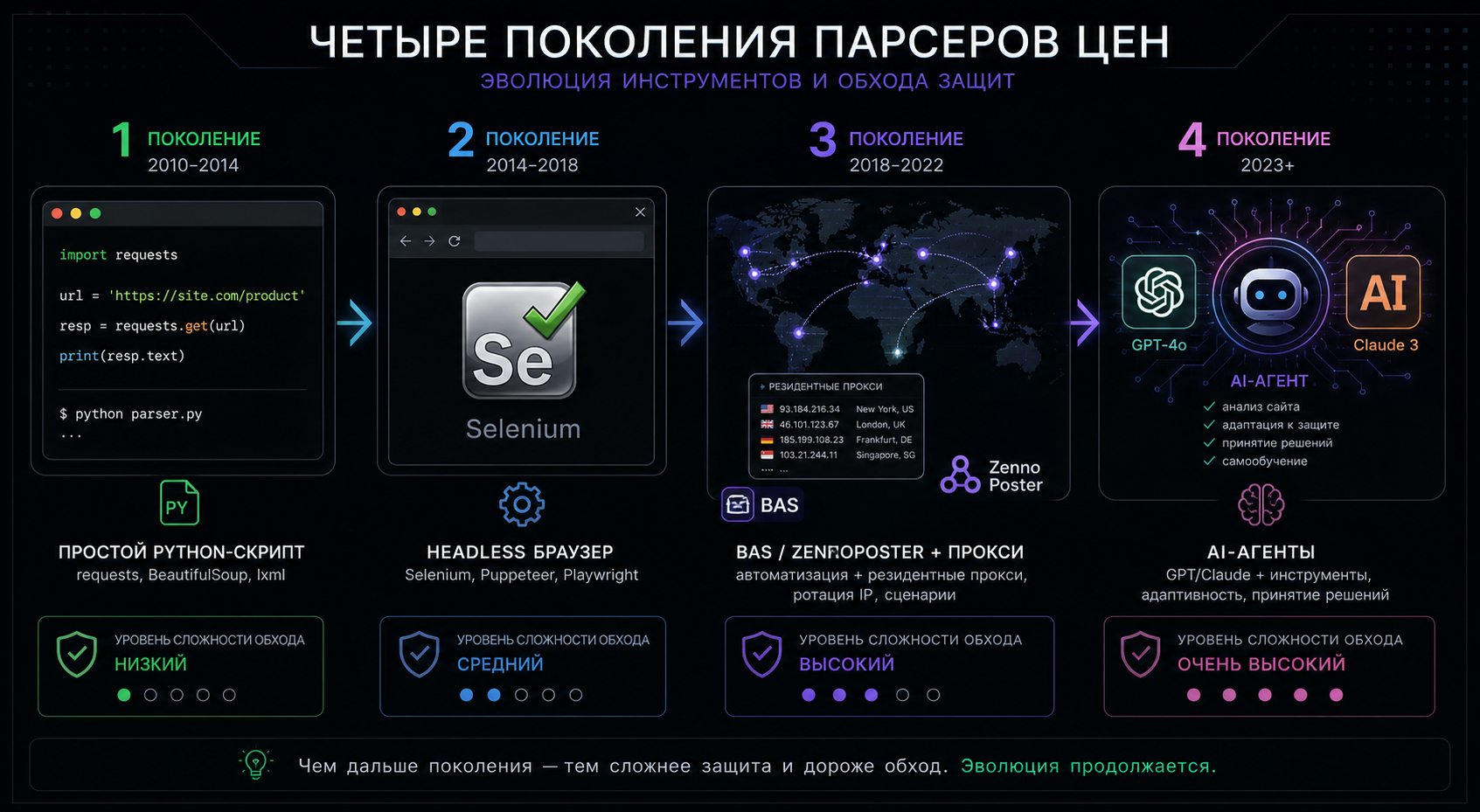
Как работают парсеры цен в 2026: четыре поколения ботов
Чтобы выбрать правильную защиту, нужно понимать, против чего вы защищаетесь. Парсер парсеру рознь: лобовой скрипт на Python библиотеке requests и облачный сервис уровня Bright Data — это совершенно разные звери, и одна reCAPTCHA на каталоге их обоих не остановит. Условно делим парсеры на четыре поколения по сложности обхода защиты.
Поколение 1 — простые HTTP-скрипты
Самый массовый класс. Скрипт на Python (requests, BeautifulSoup, Scrapy) или Node.js (axios, cheerio) ходит на ваши URL, парсит HTML, складывает в базу. Узнаётся за секунды: один-два IP, фиксированный User-Agent, отсутствие cookies, нулевое время сессии, прямой запрос на /catalog/product/12345 без захода через категорию. До 60% всего парсинг-трафика на типовом интернет-магазине — это первое поколение.
Поколение 2 — headless-браузеры
Selenium, Puppeteer, Playwright. Парсер запускает реальный Chrome/Firefox в headless-режиме, исполняет JavaScript, видит динамически подгруженные цены и отзывы. Узнаётся по специфическим JS-флагам (navigator.webdriver, неполный объект window.chrome), по бедному набору шрифтов и WebGL-данным. Уже сложнее: примитивный rate limiting не помогает, нужен браузер-fingerprinting.
Поколение 3 — поведенческая эмуляция
BAS (BrowserAutomationStudio) и ZennoPoster — российские флагманы, плюс многочисленные Anti-detect браузеры (Dolphin Anty, Multilogin, Octo). Парсер имитирует движения мыши, скроллит, делает паузы 1,5–4 секунды между действиями, подделывает canvas/WebGL, использует резидентные прокси. На уровне отдельного запроса этого парсера от пользователя на стандартных метриках не отличить — спасает только поведенческий ML и аномалии в общем потоке. Подробно — в нашей статье «Как бот имитирует пользователя».
Поколение 4 — AI-агенты
Самое свежее поколение, появилось массово в 2025: GPT-4-агенты и Claude Agent SDK, работающие как полноценный пользователь. Они «понимают» страницу, кликают по нужным кнопкам, проходят SmartCaptcha (стоимость решения у антикапча-сервисов — 2–3 ₽). От человека их пока выдают аномалии в скорости решения капчи и временные паттерны, но эта дельта быстро сужается. Готовиться надо уже сейчас.
11 методов защиты от парсинга цен интернет-магазина
Универсальной серебряной пули нет — рабочая защита всегда комбинирует базовые приёмы (отсекают первое и второе поколение) с поведенческой аналитикой и fingerprinting (отсекают третье и четвёртое). Ниже — 11 методов в порядке от простого к сложному. Внедрять можно постепенно, но эффект мультипликативный: 3 метода вместе работают сильнее, чем каждый по отдельности.
1. Rate limiting на уровне веб-сервера
Базовый и обязательный метод. В Nginx настраивается через limit_req_zone — например, 60 запросов в минуту с одного IP. Стоит сделать раздельные зоны для каталога, поиска, корзины: парсер бьёт каталог в 30 раз чаще пользователя. Минус: резидентные прокси легко обходят (один IP — один запрос, потом следующий). Поэтому это только первая линия.
2. Фильтрация по User-Agent и IP-репутации
Блокировка по User-Agent (curl, python-requests, Scrapy, Apache HttpClient) отсекает первое поколение. Чёрные списки IP — Spamhaus, AbuseIPDB, Project Honey Pot — закрывают известные ботнеты. Важный момент: не блокируйте Googlebot, YandexBot, Bingbot — иначе сайт выпадет из индекса. Используйте reverse-DNS lookup для верификации легитимных краулеров.
3. ASN-фильтрация (Autonomous System Number)
Парсеры цен преимущественно работают через датацентровые IP — AWS (ASN 16509), DigitalOcean (14061), Hetzner (24940), Google Cloud (15169), OVH (16276). Блокировка целых ASN убирает 30–50% парсеров одной директивой. Минус: режутся легитимные клиенты с VPN. Решение — выдавать капчу, а не блок. Подробнее в статье «Резидентные прокси и ASN-фильтрация».
4. Honeypot — ловушки для парсеров
Невидимая для пользователя ссылка в HTML, по которой парсер обязательно перейдёт (бот следует всем link-тегам). Например: <a href="/catalog/honeypot-12345" style="display:none"></a>. Любой IP, попавший на эту страницу, помечается как бот и блокируется на 24 часа. Эффективно против поколений 1 и 2, но третье и четвёртое часто умеют отсекать невидимые элементы.
5. Browser fingerprinting и JA3
Сбор отпечатка клиента: canvas-rendering, WebGL, шрифты, navigator-флаги, экранное разрешение, аудио-стек. На уровне TLS — JA3-хеш ClientHello. Боты с curl и Python имеют характерный JA3-фингерпринт, отличный от Chrome/Firefox. У легитимного пользователя fingerprint стабилен в рамках сессии — у плохо настроенного бота прыгает между запросами. Это ядро защиты против поколений 2 и 3. Детально — в материалах «Browser fingerprinting» и «JA3 fingerprinting».
6. Поведенческая аналитика
ML-модели на стороне сервиса защиты анализируют 30–50 поведенческих сигналов: скорость скролла, паузы между запросами, маршрут навигации, время на странице, паттерн движения мыши, последовательность кликов. Обычный пользователь сначала идёт через категорию, фильтрует, потом смотрит карточку. Парсер часто стучит сразу на /product/123, /product/124, /product/125 — это аномалия. Метод единственный, который масштабируется против AI-агентов 4-го поколения.
7. Защищённый API для подгрузки цен
Цены хранятся не в HTML, а подгружаются через AJAX/Fetch с подписанным токеном. Токен генерируется на странице через JavaScript-обфускатор и валиден 30 секунд. Парсер первого поколения видит карточку без цены и выдаёт «—». Поколения 2–4 это обходят, исполняя JS, но это удорожает парсинг и режет 70% низкокачественных скриптов. Минус: дополнительная сложность и риск задержки рендера для пользователя.
8. Подмена цены для ботов (price obfuscation)
Спорный, но действенный метод. Если запрос помечен как «вероятно бот» (скоринг 0,6–0,9), сервер отдаёт не реальную цену, а сгенерированную случайным образом в диапазоне ±15% от рыночной. Бот не понимает, что обманут — данные в его базе становятся бесполезным шумом, конкурент перестаёт ориентироваться на ваш магазин. Ключевое — точность скоринга: для пользователя ошибка катастрофична, поэтому без поведенческой аналитики метод не запускают.
9. Защита изображений и описаний
Параллельно с ценой парсят описания и фото. Защита: водяные знаки на изображениях через ResizeImageGet (Bitrix) или wp_get_attachment_image_src + плагин (WP), уникальные ALT-теги, разбавление описания «отпечатком» магазина. Не остановит парсер, но сделает контент нерелевантным для прямой публикации на чужом сайте.
10. SmartCaptcha как последний рубеж
Яндекс SmartCaptcha — российская альтернатива reCAPTCHA, бесплатна до 10 000 решений/месяц, лучше работает в РФ-выдаче. Подключается на подозрительные действия (запросы каталога без UTM-меток, прямые заходы на product-страницы, частые переходы). Не ставьте капчу всем — это убьёт конверсию. Стелс-капча через скоринг — единственный рабочий формат.
11. Готовый антибот-агент
Самый эффективный путь по соотношению трудозатрат и результата — поставить специализированный сервис защиты от ботов: BotHunt, BotFAQtor, Antibot.Cloud, Qrator. Они закрывают 9 предыдущих методов в одной интеграции (одна строка кода или плагин для CMS) и обновляются автоматически. Что ставить — зависит от бюджета и масштаба.
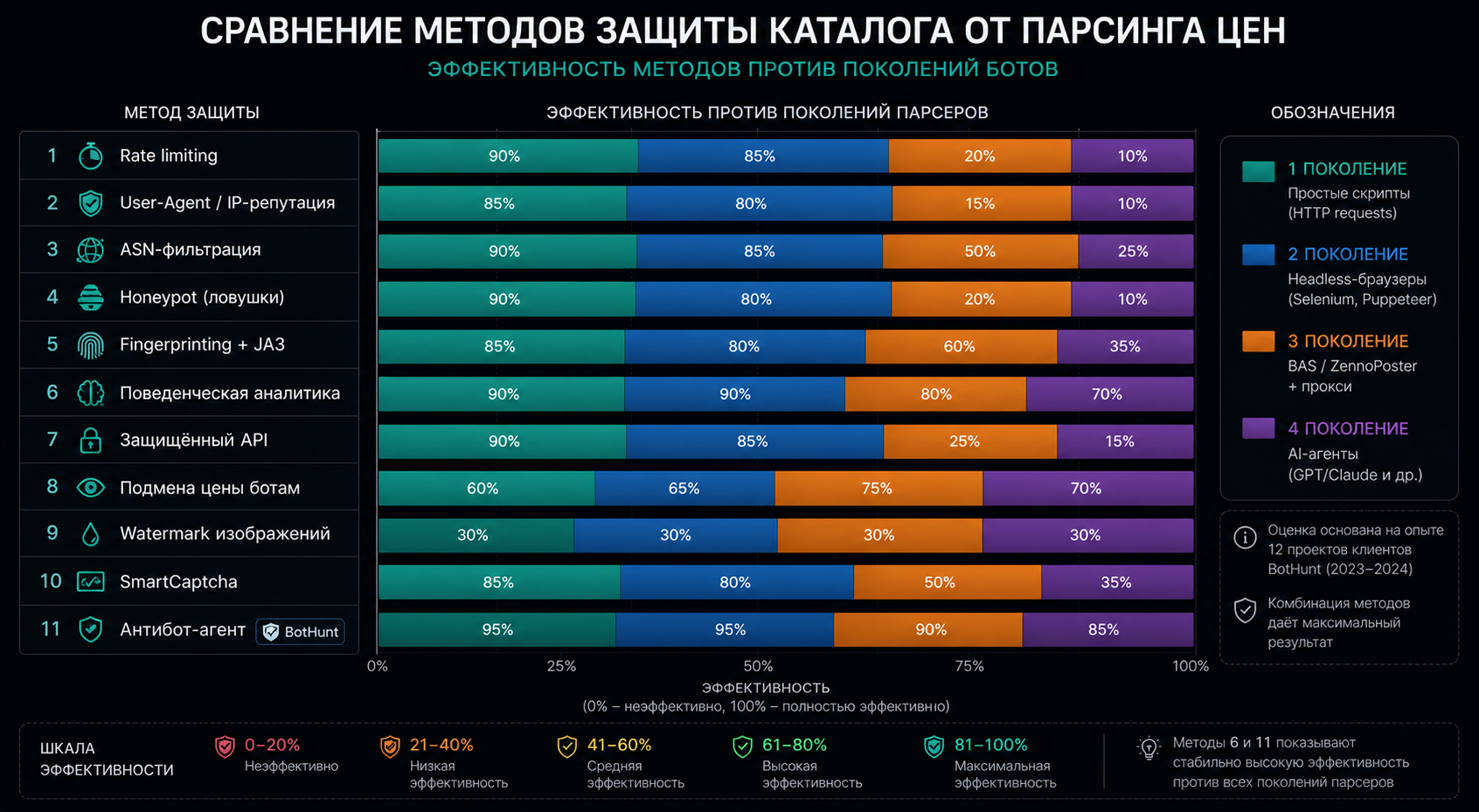
Сравнительная таблица: эффективность и стоимость методов
Чтобы быстро сориентироваться в методах, мы свели их в таблицу. Эффективность оценивали против всех четырёх поколений парсеров; стоимость — для типового интернет-магазина на 5–15 тыс. SKU. Цифры — наша внутренняя оценка по 12 проектам клиентов на агенте BotHunt.
Метод | Поколения 1–2 | Поколения 3–4 | Сложность | Стоимость в месяц | Влияние на UX |
|---|---|---|---|---|---|
1. Rate limiting | Высокая | Низкая | Низкая | 0 ₽ | Нет |
2. User-Agent / IP-репутация | Высокая | Низкая | Низкая | 0 ₽ | Нет |
3. ASN-фильтрация | Высокая | Средняя | Средняя | 0–500 ₽ | Низкое |
4. Honeypot | Высокая | Низкая | Низкая | 0 ₽ | Нет |
5. Fingerprinting + JA3 | Высокая | Средняя | Высокая | 3 000–15 000 ₽ | Нет |
6. Поведенческая аналитика | Высокая | Высокая | Высокая | в составе агента | Нет |
7. Защищённый API | Высокая | Низкая | Высокая | разработка | Низкое |
8. Подмена цены ботам | Средняя | Высокая | Высокая | в составе агента | Риск false positive |
9. Watermark изображений | Косвенная | Косвенная | Низкая | 0–1 000 ₽ | Нет |
10. SmartCaptcha | Высокая | Средняя | Низкая | 0–5 000 ₽ | Среднее |
11. Антибот-агент | Высокая | Высокая | Минимальная | 890–14 900 ₽ | Нет |
Видно, что чем «выше» метод по списку, тем шире его эффективная зона — но и сложность внедрения растёт. Оптимальный набор для среднего магазина: rate limiting + ASN-фильтрация + поведенческая аналитика + готовый агент. Это закрывает 95% парсеров без существенных затрат.
Не хотите внедрять 11 методов вручную? BotHunt закрывает все эти сценарии в одной интеграции — от плагина WordPress до агента на чистом PHP. Посмотреть тарифы →
Юридическая защита каталога: что говорит закон
Технические методы — это первая линия. Вторая — юридическая. В России базы данных интернет-магазина (структурированный массив товаров с описаниями и ценами) — это объект смежных прав по статье 1334 ГК РФ. Изготовитель базы вправе запрещать её извлечение и повторное использование без согласия в течение 15 лет.
Лицензионное соглашение и публичная оферта
Разместите на сайте «Условия использования» с явным пунктом: «Автоматизированный сбор данных из каталога без письменного разрешения запрещён». Прецедент: ВКонтакте vs Дабл (2017–2018) — суд встал на сторону площадки, признав парсинг профилей нарушением условий пользовательского соглашения и базы данных по ст. 1334 ГК РФ.
Антимонопольный аспект
Если конкурент использует ваши цены для систематического демпинга — это может квалифицироваться как недобросовестная конкуренция (ст. 14 закона «О защите конкуренции»). Жалоба в ФАС подаётся через сайт ведомства, рассматривается 1–6 месяцев. На практике штрафы небольшие, но публичность дела часто принуждает конкурента отказаться от автоматического слежения.
DMCA для зарубежных площадок
Если ваш контент перепубликован на сайте, размещённом за пределами РФ — действует DMCA (Digital Millennium Copyright Act). Через хостинг-провайдера или CDN можно потребовать удаления контента в течение 48 часов. Для текстов и фотографий метод работает; для голых цен сложнее — цены сами по себе авторским правом не охраняются.
Доказательная база
Чтобы предъявить претензию, понадобятся: логи Nginx с подозрительными User-Agent и IP, нотариально заверенный скриншот сайта-нарушителя со скопированным контентом, депонирование текстов через сервисы вроде «Текстру», экспертиза совпадения каталогов. Готовьте всё это до подачи претензии — постфактум собирать сложнее.
Готовые сценарии для CMS: Bitrix, WordPress, Tilda, OpenCart
Конкретные шаги защиты зависят от платформы. Ниже — короткие рецепты для четырёх самых популярных CMS в российском e-commerce.
1С-Битрикс
У Битрикса есть встроенный модуль «Проактивная защита», но он закрывает только базовые сценарии (rate limiting, проверка форм). Дополнительно подключите: модуль «Антипарсер» из Marketplace, переопределите шаблоны catalog.section и catalog.element для проверки скоринга, поставьте watermark через ResizeImageGet. Для серьёзной защиты — наш модуль для Битрикса, который ставит агент BotHunt в один клик.
WordPress + WooCommerce
WordPress — самая частая жертва парсинга цен из-за прозрачной структуры URL и простоты обхода стандартных плагинов вроде Wordfence. Подключите: плагин BotHunt (готов из коробки), Limit Login Attempts Reloaded (от брутфорса админки), Cloudflare Turnstile или Yandex SmartCaptcha на подозрительные действия. WooCommerce-цены подгружайте через REST API с nonce-токеном.
Tilda
Tilda — закрытая платформа, серверный rate limiting напрямую не настроить. Что доступно: подключение скриптов через Zero-блок (агент BotHunt вставляется одной строкой), блокировка через DNS-уровень (если домен на BotHunt DNS), watermark на изображениях через CDN. Тильда подгружает контент через свой CDN, что защищает от примитивных парсеров, но третье поколение проходит без проблем.
OpenCart
OpenCart часто хостится на бюджетных VPS, что усугубляет проблему перерасхода ресурсов от парсеров. Стек: модуль OpenCart Antibot (агент BotHunt, есть готовая интеграция), правила Nginx limit_req на уровне сервера, замена статичных URL вида /index.php?route=product/product&product_id=42 на ЧПУ — это путает примитивные парсеры. Дополнительно — отключение «универсального» XML-фида для всех.
Чек-лист внедрения защиты от парсинга цен за 7 дней
Если у вас нет специалиста по безопасности — двигайтесь по этому плану. Каждый день — одна задача длительностью 1–3 часа.
День 1. Аудит. Запустите curl --user-agent "python-requests/2.31.0" https://ваш-сайт/catalog/ — если вернулась полная страница без задержки и капчи, защиты у вас нет. Откройте логи Nginx за последние 7 дней и сгруппируйте по User-Agent — увидите топ ботов в трафике.
День 2. robots.txt и базовые директивы. Закройте /admin, /api, /search для всех User-Agent кроме Googlebot и YandexBot. Подробнее — в статье «robots.txt: мифы и реальные возможности».
День 3. Rate limiting. Настройте Nginx limit_req_zone — 60 req/min для каталога, 20 req/min для поиска, 5 req/min для корзины.
День 4. ASN-фильтрация. Подключите MaxMind GeoLite2 ASN или модуль ngx_http_geoip2 — отдавайте капчу всем визитам с ASN AWS, DigitalOcean, Hetzner, OVH.
День 5. Honeypot. Добавьте скрытую ссылку /catalog/honeypot-trap в подвале сайта; в access-log настройте автоматическую блокировку IP, который туда ходит. Параллельно поищите парсеров методами из статьи «Как обнаружить парсер на сайте».
День 6. Поведенческая аналитика. Подключите BotHunt (одна строка кода или плагин CMS) — он заменит весь стек fingerprinting + ML без вашего участия.
День 7. Контрольный аудит. Повторите curl-проверку из пункта 1, посмотрите дашборд BotHunt с отсечёнными ботами, сравните метрики Метрики до и после.
Как BotHunt отсекает парсеры цен в реальном времени
Поскольку статья про защиту, не упомянуть свой продукт мы не можем. BotHunt — российский SaaS, построенный именно на 5-м, 6-м и 11-м методах из нашего списка: поведенческая аналитика, fingerprinting и готовый агент. Большую часть из 11 методов агент закрывает «из коробки», без отдельной настройки.
Как это работает
На сайт ставится одно из трёх: PHP-агент в bootstrap (one-liner), плагин для WordPress/Bitrix/OpenCart или DNS-проксирование (если не хотите трогать код). Каждый запрос анализируется по 40+ сигналам: TLS JA3, Canvas/WebGL fingerprint, IP-репутация, ASN, поведение в сессии, скорость движения мыши, временные паттерны. Решение принимается за 4–12 миллисекунд (по нашему SLO — медиана 7 мс), это незаметно для пользователя.
Что увидите в дашборде
Карта парсеров по странам и ASN, top User-Agent, графики «реальный трафик vs боты», подробный лог по каждому заблокированному запросу с указанием причины (например: «JA3 совпадает с Python requests, ASN — DigitalOcean, без referer»). Можно настроить алерт в Telegram при всплеске ботов: «У вас +320% парсеров в категории iPhone за последний час».
Совместимость с SEO
Один из частых страхов — «я закрою парсеров и заодно Яндекс с Гуглом». BotHunt поддерживает белый список легитимных краулеров (актуализируется ежедневно по реверс-DNS) и пропускает Googlebot, YandexBot, Bingbot, DuckDuckBot. AI-боты (GPTBot, ClaudeBot) — настраиваются отдельно: вы можете оставить их (если хотите быть в ChatGPT) или закрыть.
Цены
Тариф Site (один сайт) — 890 ₽/месяц, без лимита по запросам. Studio (5 сайтов) — 2 990 ₽. Agency (20) — 7 990 ₽. Pro (100) — 14 900 ₽. Первые 14 дней бесплатно без привязки карты. Для интернет-магазина с трафиком 200–500 тыс. визитов/месяц это копейки относительно потерянной маржи на демпинге.
Защитите каталог от парсинга за 1 минуту — установите BotHunt бесплатно на 14 дней без привязки карты. Подключить агент →
Часто задаваемые вопросы
Можно ли полностью запретить парсинг цен на сайте?
Полностью — нет, и любой, кто это обещает, лукавит. Цена в открытом каталоге доступна по определению, и в крайнем случае конкурент посадит человека вручную обходить страницы. Но реалистичная задача — сделать парсинг настолько дорогим (по времени, прокси, антикапче), чтобы он стал экономически нецелесообразным. По нашим данным, после подключения BotHunt средний бюджет конкурента на парсинг растёт в 8–15 раз — большинство просто переключается на других.
Не пострадают ли позиции в Яндексе и Google от защиты от парсинга?
При правильной настройке — нет. Все известные сервисы защиты (включая BotHunt) пропускают легитимных краулеров через белый список и реверс-DNS-проверку. Опасность возникает, если вы пишете правила Nginx руками и блокируете по User-Agent «Yandex» — тогда YandexBot тоже попадает под запрет. Используйте готовые сервисы или сверяйтесь со списком IP-диапазонов в Яндекс.Справке для вебмастеров и Google Search Console.
Можно ли подменять цены для парсеров — это законно?
Да, законно — речь идёт о вашем сайте и собственном HTML-ответе. Прямого запрета на price obfuscation в законодательстве нет. Главное — не показывать ложные цены реальным пользователям (это уже потребительское право и риск штрафов от Роспотребнадзора). Поэтому метод используют только в связке с поведенческим скорингом высокой точности.
Сколько стоит защита от парсинга в месяц?
Зависит от подхода. Своими руками: настройка Nginx + плагин CMS + reCAPTCHA — бесплатно, но 15–25 часов работы DevOps плюс постоянная поддержка. Готовое решение: BotHunt — от 890 ₽/месяц за один сайт. Cloudflare Bot Management в России официально не работает с 2022. Enterprise (Qrator, NGENIX) — от 30 000 ₽/месяц. Для интернет-магазина с каталогом до 50 000 SKU оптимум — SaaS-агент за 1 000–3 000 ₽.
Поможет ли robots.txt против парсера цен?
Нет, не поможет. robots.txt — это вежливая просьба, которую соблюдают только Googlebot, YandexBot и Bingbot. Парсеры конкурентов её игнорируют по умолчанию: ни Python-скрипт, ни Selenium robots.txt не проверяют. Файл нужен для управления индексацией поисковиков, а не для защиты. Подробный разбор — в статье «robots.txt: мифы и реальные возможности».
Как защитить цены, которые подгружаются через AJAX?
Защищайте API так же, как HTML. Ставьте подписанный nonce-токен в запросе (генерируется на странице, валиден 30 секунд), CSRF-проверку, rate limiting на эндпоинт /api/products/price (более жёсткий, чем на каталог), проверку Origin-заголовка. Для дополнительной защиты — ротация публичного API-ключа раз в сутки и логирование всех вызовов с скорингом BotHunt.
Парсер обходит мою reCAPTCHA — что делать?
Обычно reCAPTCHA v2 (с галочкой «Я не робот») обходится через антикапча-сервисы за 1,5–3 ₽ за решение. Что помогает: переход на reCAPTCHA v3 invisible с пороговым скорингом, либо Яндекс SmartCaptcha с поведенческой моделью, либо отказ от капчи в пользу проактивной защиты — поведенческой аналитики и fingerprinting. Капча — это не «стена», это «турникет», который не остановит мотивированного парсера.
Стоит ли блокировать резидентные прокси полностью?
Нет, в большинстве случаев нет. Под резидентными прокси сидят легитимные пользователи мобильного интернета (МТС, МегаФон, Билайн), сотрудники компаний за корпоративными VPN, пользователи Tor (если он не запрещён в ваших ToS), AI-инструменты вашего же отдела маркетинга. Блокировка целиком даст 5–15% false positive. Правильный путь — выдавать капчу или повышать скоринг подозрительности, а блокировать только при совпадении с другими сигналами (JA3 + поведение).


