

По нашим данным в BotHunt, в среднем 18-35% входящего трафика на коммерческие сайты в Рунете — это парсеры и скрейперы. У интернет-магазинов и агрегаторов доля доходит до 60%, у B2B-каталогов — до 70%. Каждый такой запрос грузит сервер, искажает метрики в Яндекс Метрике, утекает в виде каталога и цен в чужие руки и в обучающие выборки нейросетей. Защита сайта от парсеров в 2026 году перестала быть «опциональной» — она нужна каждому коммерческому проекту наравне с HTTPS и резервным копированием.
В этом руководстве разбираем 15 рабочих методов защиты — от базовых (robots.txt, rate limiting) до продвинутых (TLS-fingerprinting, ML-детекция). Сравниваем их эффективность в таблице, разбираем юридическую сторону, типичные ошибки и даём пошаговый план запуска защиты за 1 день.
Кто и зачем парсит сайты в 2026 году
Парсинг (или скрейпинг) — это автоматизированный сбор информации со страниц чужого сайта. В 2026 году это огромная индустрия: на одной только бирже Kwork по запросу «парсер сайта» — сотни предложений ценой от 500 рублей за разовую выгрузку. Среди заказчиков:
Конкуренты — маркетологи и категорийные менеджеры. Снимают ваш каталог и цены раз в час, чтобы держать свои на 1-2% ниже. По нашей статистике, в e-com 35-60% всех визитов парсеров приходятся именно на этот сценарий.
Агрегаторы и маркетплейсы. Заполняют каталог чужими карточками, картинками и описаниями. Часто без согласования и без ссылки на источник.
AI-компании и LLM-краулеры. GPTBot, ClaudeBot, PerplexityBot, Google-Extended — собирают тексты для обучения моделей. Часть представляется честным User-Agent, часть маскируется под обычный Chrome.
Перепродавцы данных. Парсят базы B2B-контактов, отзывы, новости, чтобы продавать «свежий датасет» в Telegram-каналах.
Скрипт-кидди. Ученики курсов по веб-скрейпингу: запускают примитивный скрипт «спарсить весь рунет» и не глядя кладут серверы.
Цена вопроса для жертвы — от испорченных метрик и потери конверсии до штрафа Роскомнадзора (если в выгрузке оказались персональные данные клиентов) и судебных тяжб. Подробнее про защиту цен интернет-магазина — в нашей статье про парсинг цен.
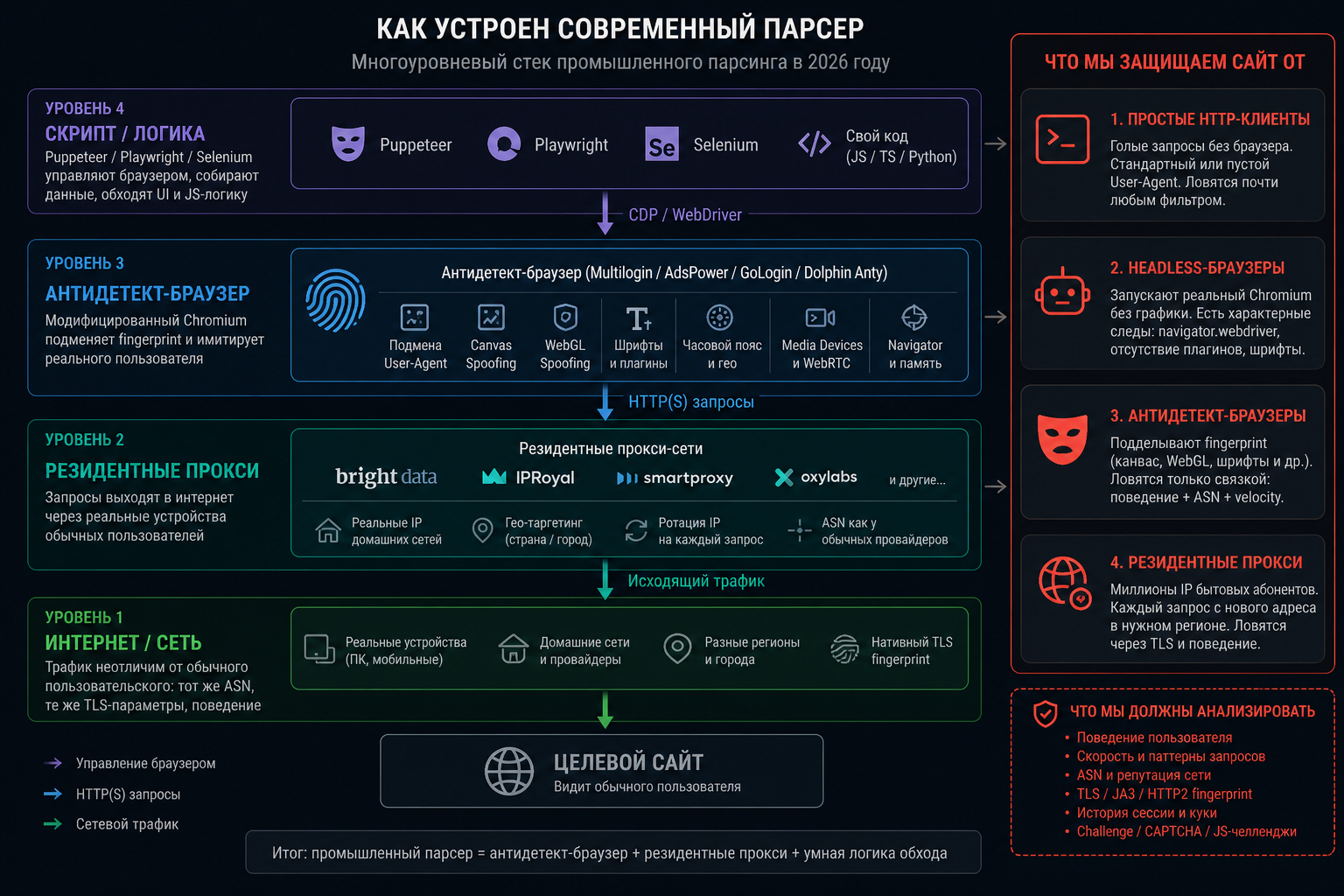
Как устроен современный парсер: что мы защищаем сайт от
Чтобы защита работала, надо понимать, чем вооружён противник. В 2026 году парсеры делятся на четыре уровня сложности:
Простые HTTP-клиенты. Скрипты на Python (requests, httpx, aiohttp) или Node.js (axios). Не запускают браузер, шлют голый HTTP-запрос. Стандартный User-Agent или вовсе пустой. Ловятся почти любым адекватным фильтром.
Headless-браузеры. Puppeteer, Playwright, Selenium запускают реальный Chromium без графики. Получают полностью отрендеренный DOM, исполняют JS, проходят простые challenge. Обходятся фингерпринтингом — у headless всегда есть характерные следы (свойство navigator.webdriver, отсутствие плагинов, специфические шрифты).
Антидетект-браузеры. Multilogin, AdsPower, GoLogin, Dolphin Anty — модифицированные сборки Chromium с подделкой fingerprint. Канвас, WebGL, шрифты — всё рандомизируется на каждый профиль. Ловятся только связкой «поведение + ASN + velocity».
Резидентные прокси-сети. Bright Data, IPRoyal, Smartproxy дают доступ к десяткам миллионов IP бытовых абонентов. Каждый запрос идёт с нового адреса в нужном регионе. Ловятся через TLS-fingerprint и поведенческую аналитику.
Большая часть промышленного парсинга в Рунете в 2026 году — это сочетание антидетект-браузера и резидентных прокси. Один такой комплект стоит 200-500 долларов в месяц и обеспечивает полную незаметность для CDN-фильтров типа robots.txt и обычной CAPTCHA. Подробный разбор — в материале «Как бот имитирует пользователя».
15 методов защиты сайта от парсеров: что реально работает
Ни один метод по отдельности в 2026 году не даёт 100% защиты — продвинутый парсер обойдёт любую одиночную проверку. Реально работает многослойная оборона: бот должен пройти 3-4 независимых рубежа. Ниже — все 15 методов с честной оценкой того, против каких парсеров они работают.
Метод 1. Файл robots.txt и meta noindex
Базовая «вежливая просьба» не парсить. В файле robots.txt в корне сайта прописываются директивы Disallow и блокировки User-Agent для конкретных краулеров. Например, чтобы попросить уйти GPTBot:
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /Работает только против добросовестных ботов — поисковых систем и официальных AI-краулеров, которые соблюдают стандарт. Парсеру конкурента или спам-боту robots.txt вообще не указ — они его не читают. Подробнее, что реально умеет robots.txt и в чём его границы, мы пишем в отдельной статье про мифы robots.txt.
Метод 2. Rate limiting и anti-flood
Ограничение количества запросов с одного IP в минуту/час. Настраивается на уровне Nginx (модуль limit_req), Apache (mod_evasive) или CDN. Базовая рекомендация для каталога: не более 60 GET-запросов в минуту с одного IP, не более 5 POST-запросов в минуту.
Помогает против простых HTTP-парсеров, которые ломятся в 100 потоков. Бесполезен против резидентных прокси, где каждый запрос идёт с нового IP. И опасен жёсткими настройками: режет мобильных пользователей под общим NAT и корпоративные сети. Мы рекомендуем адаптивный rate limit, который зависит от score клиента, а не от факта запроса.
Метод 3. Блокировка по User-Agent
Чёрный список заголовков: python-requests, curl, Scrapy, Java, Go-http-client. Реализация — одна строчка в конфиге Nginx или в WAF. Эффективна против скрипт-кидди и простых тестов, потому что серьёзный парсер всегда подменяет User-Agent на актуальный Chrome 124. Используйте этот фильтр как «первый отсев», но никогда — как единственный рубеж.
Метод 4. Фильтрация по ASN и репутации IP
ASN (Autonomous System Number) показывает, к какой сети принадлежит IP: дата-центру, бытовому провайдеру, мобильному оператору, VPN-сервису. У промышленных парсеров на голых VPS почти всегда ASN дата-центров (Hetzner, OVH, DigitalOcean, Selectel, Beget). Простой фильтр «никаких визитов к каталогу с дата-центровых ASN» режет 25-40% всего паразитного трафика.
Дополнительно — репутационные базы (FireHOL Level 1-3, Spamhaus, AbuseIPDB) с известными «грязными» диапазонами. Тонкость: антидетект-парсеры заходят с резидентных IP, и тут ASN-фильтр помогает мало. Подробно про это — в обзоре резидентных прокси.
Метод 5. JS-challenge до рендера страницы
Прозрачный «вызов» на JavaScript: подозрительному клиенту до выдачи HTML предлагается решить лёгкую задачу — вычислить токен, подписать nonce, выполнить proof-of-work. Реальный браузер справляется за 50-200 мс, пользователь не замечает. Простой парсер на requests, который вообще не исполняет JS, — отваливается.
Headless-браузер JS-challenge проходит, но это резко удорожает парсинг: вместо 1000 страниц в минуту через requests парсер выжимает 30-50 через Puppeteer и тратит CPU. Для сценария «снимать каталог раз в час» это уже нерентабельно. В BotHunt JS-challenge применяется только к визитам со score выше порога, чтобы не нагружать клиентских пользователей.
Метод 6. Honeypot-поля и страницы-ловушки
Невидимая для человека «приманка», на которую попадается только автоматизация. Два сценария:
Honeypot-поле в форме. Скрытый через CSS input, который человек никогда не заполнит. Бот, тупо проходящий по DOM, заполняет его и улетает в бан. Особенно эффективно против спам-ботов в формах обратной связи.
Honeypot-страница в каталоге. Невидимая для пользователя ссылка типа /system/internal-prices.html. Простой скрейпер обходит DOM через querySelectorAll и заходит туда. Все IP и fingerprint, попавшие на ловушку, помечаются как боты на 30 дней.
Метод хорош нулевыми ложными срабатываниями (живой человек физически не дойдёт до ловушки) и тем, что противник не знает, где она. Минус — требует настройки и регулярной ротации, иначе ловушки попадают в стоп-листы парсеров.
Метод 7. Browser fingerprinting
Сбор «цифрового отпечатка» браузера: canvas-рендер, WebGL, набор шрифтов, плагины, разрешение экрана, часовой пояс, набор поддерживаемых аудиокодеков. Полный fingerprint включает 80-150 параметров и почти уникален: вероятность совпадения у двух разных людей — 1 на миллион.
Антидетект-браузеры рандомизируют fingerprint на каждый профиль, но делают это статистически плохо: канвас даёт характерные округлённые значения, WebGL-рендер выдаёт виртуальную видеокарту SwiftShader, набор шрифтов слишком короткий. Хорошая модель ловит антидетект с точностью 92-97%. Глубокий разбор — в нашей статье про browser fingerprinting.
Метод 8. TLS/JA3-fingerprinting
JA3 — отпечаток клиента на уровне TLS-handshake (порядок шифров, расширений, эллиптических кривых). Уникален для каждой связки «библиотека + версия + ОС». У requests Python — один JA3, у Chrome 124 на Windows — другой, у Chrome 124 на Linux — третий. Подделать JA3 в обычном HTTP-клиенте без модификации библиотеки практически невозможно.
Это «убийца» простых парсеров: фильтр на JA3 ловит весь трафик с requests/aiohttp/httpx за один запрос, не дожидаясь даже HTTP-заголовков. Поддерживается на уровне Nginx через модуль njs или в готовых WAF. Подробнее — в статье про JA3-fingerprinting.
Метод 9. Поведенческая аналитика в реальном времени
Если предыдущие методы отвечают на вопрос «кто это», поведенческая аналитика отвечает «как он себя ведёт». ML-модель смотрит на:
движение мыши (живой человек — микро-дрожание, бот — ровные отрезки или вообще нет курсора);
скорость и паузы при скролле;
последовательность кликов (человек кликает по разным элементам, бот — строго по схеме);
временные интервалы между запросами (у автоматизации они слишком одинаковые);
глубину просмотра и распределение времени по страницам.
Главный плюс — метод не зависит от того, насколько хорошо парсер маскируется на сетевом уровне. Главный минус — нужна ML-модель, обученная на миллиардах визитов; самостоятельно построить такое для одного сайта нереально, поэтому обычно покупают как часть SaaS-антибота.
Метод 10. Динамический рендер контента через JavaScript
Контент (особенно цены, остатки, контакты) подгружается не в исходном HTML, а через AJAX или React/Vue после загрузки страницы. Парсер, который скачивает только HTML без исполнения JS, получает пустую разметку. Это режет 60-80% «дешёвых» парсеров.
Минусы: ухудшает индексацию в поисковиках, если рендер не настроен под Googlebot/YandexBot (нужен SSR или динамический рендеринг по User-Agent). И не помогает против Puppeteer/Playwright — те исполняют JS и забирают итоговый DOM. Используйте как один из слоёв, а не как единственную защиту.
Метод 11. Обфускация HTML и ротация классов
Парсеры цепляются за CSS-селекторы и атрибуты вроде .product__price или data-id. Если на каждый деплой эти селекторы меняются (например, классы Tailwind с хешем сборки + рандомизация), парсер ломается и требует ручной перенастройки. Полезно против лонгран-парсеров, которые работают месяцами по одному скрипту.
Минусы — усложняет отладку и собственное A/B-тестирование, ломает интеграции с внешними инструментами (Метрика-цели по селекторам, Hotjar). Лучше применять выборочно: рандомизировать только критические данные (цены, остатки), оставив остальное стабильным.
Метод 12. Канареечные данные (canary tokens)
В каталог подмешиваются уникальные «маркеры»: товар-ловушка с приметным названием, ложная цена с нестандартным окончанием (например, 19 999,17 ₽), сгенерированный email в контактах. Если эти маркеры всплывают на чужом сайте — у вас есть железное доказательство парсинга и его направления. На основании этого можно предъявлять претензию или иск.
Метод не блокирует парсер, но даёт юридический рычаг и даёт возможность отслеживать утечку. Используйте параллельно с техническими мерами.
Метод 13. Защита изображений: watermark и адаптивные форматы
Если опасна не текстовая часть, а фотографии (товары, объекты недвижимости, авто), помогает многослойная защита изображений:
видимый watermark с доменом сайта на фотографии;
цифровой watermark в EXIF/IPTC (невидимый, но позволяет доказать происхождение);
разные URL для разных размеров — парсер тащит только превью, оригинал получает только реальный пользователь после действия;
blob-URL вместо прямой ссылки на CDN — фото нельзя скачать через wget.
Метод 14. llms.txt и блокировка AI-ботов
Стандарт llms.txt (предложен в 2024 году) — отдельный файл в корне сайта, который описывает, какие разделы можно использовать LLM-краулерам, а какие нельзя. В отличие от robots.txt, он семантически богаче: можно указать, что разрешён только статус-цитирование, но не использование в обучающей выборке.
Параллельно — блокировка User-Agent основных AI-ботов на уровне Nginx или WAF: GPTBot, ChatGPT-User, ClaudeBot, anthropic-ai, PerplexityBot, Google-Extended, FacebookBot, Bytespider, Amazonbot. Подробный гайд — в нашей статье про защиту от AI-ботов.
Метод 15. Специализированный антибот-сервис
Готовое SaaS-решение, которое объединяет в себе методы 4-9: ASN-фильтрацию, JS-challenge, browser fingerprinting, JA3, поведенческую аналитику, ML-детекцию и общую базу репутации на десятках миллионов фингерпринтов. Подключается одной строкой кода или плагином CMS.
Мы в BotHunt построили такой сервис под российский рынок: агент срабатывает за <100 мс, фильтрует парсеры всех четырёх уровней (от requests до антидетектов с резидентными прокси), не блокирует поисковые роботы (YandexBot, GoogleBot валидируются по обратному DNS), даёт дашборд с разбивкой угроз. Точность детекции скрейперов — 99,4% при ложных срабатываниях ниже 0,1%. Развёртывание — в среднем 1-5 минут на WordPress, Bitrix, Tilda, Django и других стеках.
Подключите BotHunt на 14 дней бесплатно — установка занимает 1 минуту, и вы сразу увидите, сколько парсеров ходит по сайту прямо сейчас. Запустить защиту →
Сравнительная таблица 15 методов защиты от парсеров
Сводка для тех, кто хочет одним взглядом понять, какие методы стоят свеч. Колонки: эффективность против простых парсеров (requests/curl), против headless-браузеров (Puppeteer), против антидетектов с резидентными прокси, и сложность настройки.
№ | Метод | Простые парсеры | Headless | Антидетект+прокси | Сложность |
|---|---|---|---|---|---|
1 | robots.txt | Нулевая | Нулевая | Нулевая | Минимум |
2 | Rate limiting | Высокая | Средняя | Нулевая | Низкая |
3 | User-Agent фильтр | Высокая | Низкая | Нулевая | Минимум |
4 | ASN/IP-репутация | Высокая | Высокая | Средняя | Средняя |
5 | JS-challenge | Очень высокая | Высокая | Средняя | Средняя |
6 | Honeypot | Высокая | Высокая | Высокая | Средняя |
7 | Browser fingerprinting | Очень высокая | Очень высокая | Высокая | Высокая |
8 | JA3/TLS fingerprinting | Очень высокая | Высокая | Средняя | Высокая |
9 | Поведенческая аналитика | Очень высокая | Очень высокая | Очень высокая | Очень высокая |
10 | Динамический рендер | Высокая | Низкая | Низкая | Высокая |
11 | Обфускация HTML | Средняя | Средняя | Низкая | Высокая |
12 | Canary-токены | Только трекинг | Только трекинг | Только трекинг | Низкая |
13 | Защита изображений | Только частично | Только частично | Только частично | Средняя |
14 | llms.txt + UA AI-ботов | Только честные AI | Только честные AI | Только честные AI | Низкая |
15 | Антибот-сервис (BotHunt) | Очень высокая | Очень высокая | Очень высокая | Низкая |
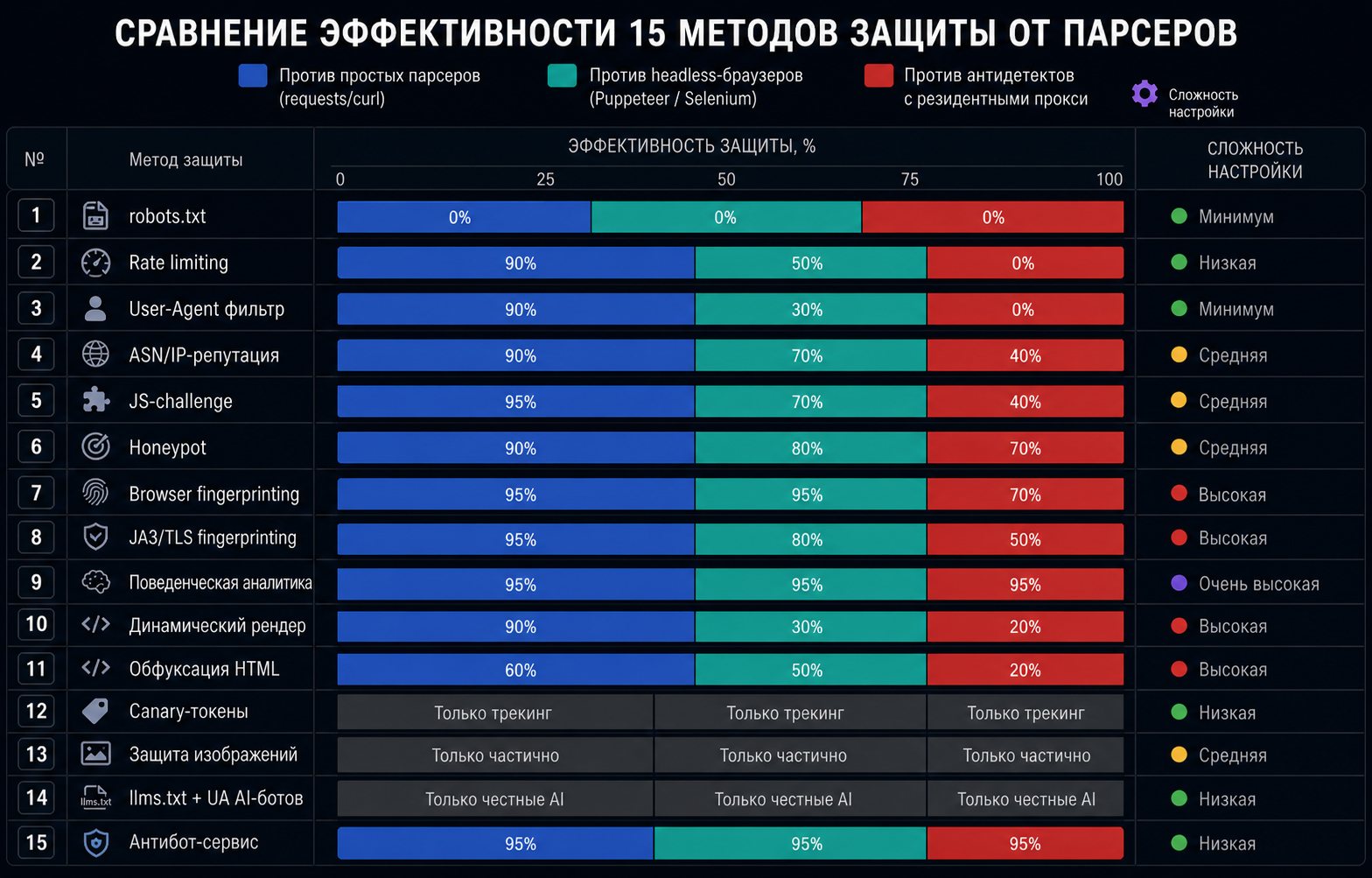
Главный вывод из таблицы: ни один отдельный метод не закрывает все классы парсеров. Базовые методы (1-4) работают только против скрипт-кидди. Серверные продвинутые (5-8) добивают headless. Антидетекты с резидентными прокси останавливаются только связкой 7-9 + 15. Поэтому реалистичная защита — это «лестница» из 4-6 методов разного уровня.
Юридическая сторона парсинга в России
Технические меры — это первая линия. Вторая — юридическая. В РФ парсинг сам по себе не запрещён, но есть несколько норм, по которым можно отстоять свои данные:
Статья 1334 ГК РФ — право изготовителя базы данных. Если ваш каталог требовал «существенных финансовых, материальных, организационных или иных затрат», он защищён как база данных. Конкурент, скопировавший «существенную часть», нарушает закон. На практике проходят иски по выгрузкам объёмом более 10 тыс. карточек.
Статья 1259 ГК РФ — авторское право на контент. Уникальные описания, фотографии, обзоры — объекты авторских прав. Парсер, скопировавший их без согласия, нарушает закон. Особенно надёжно при наличии депонирования или хотя бы датированных публикаций.
152-ФЗ «О персональных данных». Если парсятся анкеты пользователей, отзывы с указанием имён и контактов — это сбор персональных данных без согласия субъекта. Штрафы в 2025 году выросли: до 18 млн рублей для юрлиц и до 1,5 млн — для ИП.
Договорные оговорки (User Agreement). В пользовательском соглашении прописывается прямой запрет на автоматизированный сбор данных. Это даёт основание для иска о нарушении договора, даже если интеллектуальной собственности формально нет.
Важная оговорка: суды в РФ принимают иски, когда есть доказательства источника. Поэтому методы 12 (canary-токены) и 13 (watermark на фото) важны не только для технической защиты, но и как готовая доказательная база. Подробнее про юридическую практику — в материалах Хабра по парсингу.
Не уверены, кто и как парсит ваш сайт? Запросите бесплатный аудит трафика — мы покажем долю парсеров, их источники и порекомендуем стек защиты под ваш проект. Посмотреть тарифы →
Частые ошибки при защите от парсеров
В практике мы видим одни и те же грабли. Чек-лист, чтобы их обойти:
Ошибка | Чем чревато | Как правильно |
|---|---|---|
Полностью закрыть сайт от ботов через robots.txt | Сайт пропадает из поиска вместе с парсерами | Точечная блокировка только AI-краулеров и плохих UA |
Поставить reCAPTCHA на каждую страницу | Падение конверсии 15-30%, парсеры обходят anti-captcha сервисами | Прозрачный JS-challenge только подозрительным визитам |
Заблокировать все ASN дата-центров | Режет VPN-пользователей, удалёнщиков, корпоративные шлюзы | Использовать ASN как один сигнал из многих |
Отдавать «пустой» HTML и грузить всё через JS | Падение позиций в Яндексе и Google, плохой Lighthouse | SSR + динамический рендеринг по User-Agent поисковика |
Менять CSS-селекторы каждый деплой | Ломается своя аналитика, A/B-тесты, интеграции | Обфускация только критичных полей (цены, остатки) |
Думать «у нас нет важных данных» | Парсеры жмут сервер, искажают метрики, обучают чужие LLM | Ставить базовую защиту на всё, что доступно публично |
Полагаться только на CDN/WAF | CDN ловит DDoS и инъекции, не ловит «вежливых» парсеров | Антибот + WAF — это два разных слоя, нужны оба |
Особенно хочется выделить последний пункт. Cloudflare и российские WAF (Solar, PT AF) хорошо ловят сетевые атаки, но плохо отличают «обычный браузер с прокси и автоматизацией» от живого пользователя. Подробнее — в материале «WAF vs антибот: в чем разница».
Пошаговый план запуска защиты от парсеров за 1 день
Реалистичный план для владельца сайта, который сегодня впервые задумался о защите. Срок — 4-6 часов работы, эффект — заметный в Метрике уже на следующий день.
Диагностика (30-60 мин). Откройте в Метрике отчёт «Источники → Прямые заходы и роботы», в Вебмастере — раздел «Индексирование → Статистика обхода». Сверьте логи Nginx за последние 7 дней (отчёт в статье про логи). Зафиксируйте долю подозрительного трафика и его источники.
Базовый санитарный минимум (60 мин). Включите rate limiting в Nginx (60 req/min для GET, 5 req/min для POST). Добавьте в robots.txt блокировку GPTBot, ClaudeBot, PerplexityBot. В WAF/Nginx включите фильтр по нежелательным User-Agent.
Подключение антибот-сервиса (10 мин). Зарегистрируйтесь в BotHunt, добавьте сайт. Установите агент: на WordPress — плагин из репозитория, на Bitrix/Tilda/кастомных движках — одна строка JavaScript в шапку. Первые 30 минут сервис калибруется на вашем трафике.
Настройка ловушек (60-90 мин). Добавьте 2-3 honeypot-страницы в каталог (невидимые ссылки). На странице пользовательского соглашения пропишите явный запрет автоматизированного сбора данных. Создайте 1-2 canary-товара с уникальными названиями для отслеживания утечки.
Мониторинг 7 дней. Каждый день смотрите в дашборде BotHunt: какой процент трафика оказался ботами, какие классы преобладают (HTTP-парсеры, headless, антидетекты), нет ли ложных срабатываний на ваших клиентов. При необходимости настройте белый список для корпоративных сетей и партнёрских интеграций.
Юридическая подготовка (фоном). Параллельно соберите доказательную базу: депонируйте уникальные описания и фото, актуализируйте пользовательское соглашение. Если canary-токены утекут на чужой сайт — у вас уже будут готовые шаги для досудебной претензии.
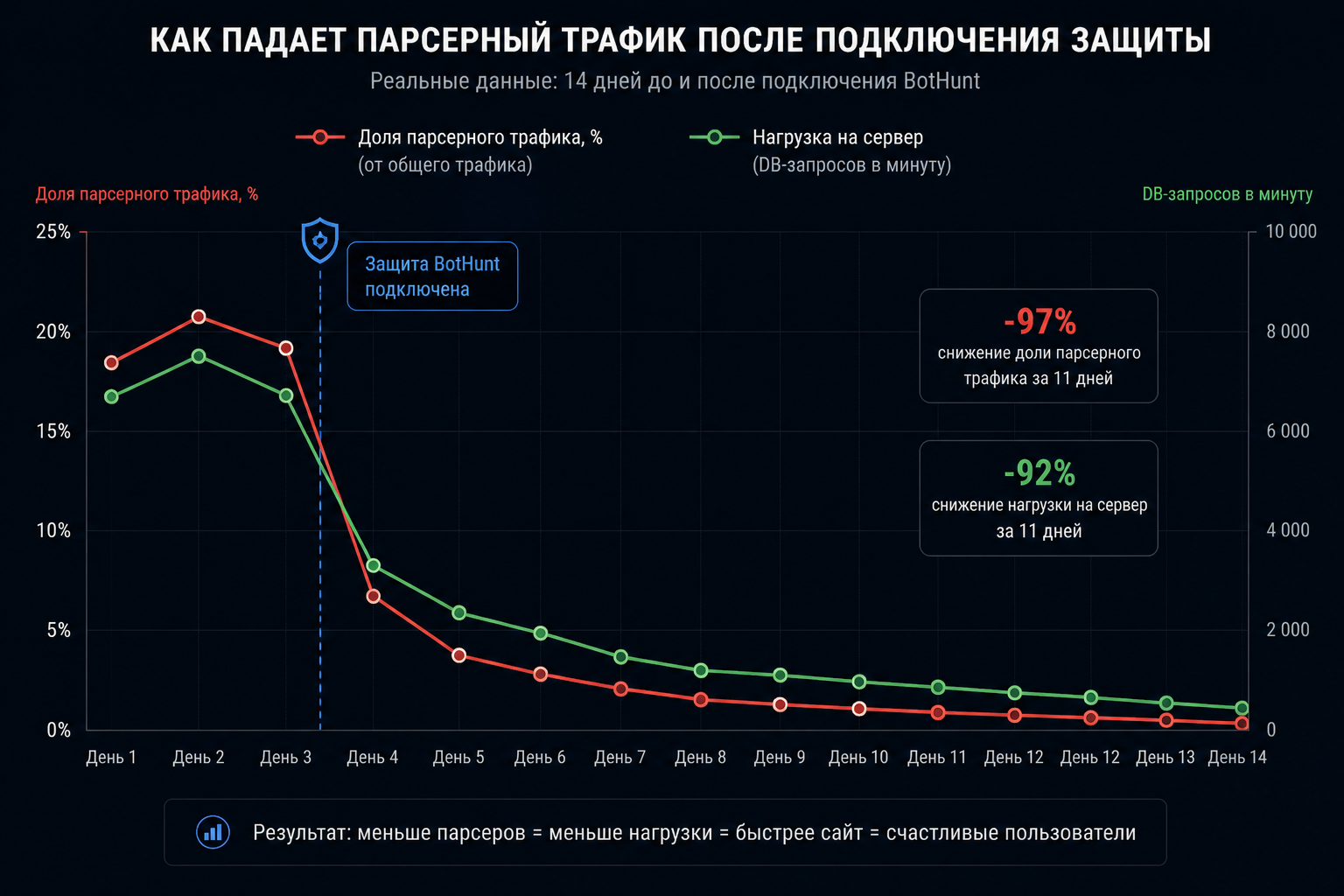
Типичная картина после внедрения: в первые 3-5 дней дашборд показывает реальную долю парсеров (обычно 20-50% всего трафика, в e-com может быть до 70%). Через 2 недели падают искажения в Метрике (отказы, время на сайте, география), нагрузка на сервер снижается на 15-40%, освобождается база Postgres от хитов в карточки товаров. Через месяц можно увидеть восстановление позиций в Яндексе — за счёт того, что поведенческие сигналы стали реальными.
Запустите защиту BotHunt бесплатно — 14 дней без привязки карты, точная диагностика парсеров на вашем трафике с первого дня. Начать защиту →
Часто задаваемые вопросы
Можно ли полностью защитить сайт от парсеров?
Полностью — нет. Любой контент, который видит пользовательский браузер, в конечном счёте можно прочитать программой. Реалистичная цель — сделать парсинг экономически невыгодным: увеличить стоимость одного спарсенного товара в 50-100 раз. Многослойная защита (методы 4-9 + 15 из этой статьи) этого добивается, и большинство парсеров уходят к менее защищённым конкурентам.
Не повредит ли защита от парсеров SEO?
Нет, если защита настроена правильно. BotHunt и грамотные WAF валидируют поисковые роботы (YandexBot, GoogleBot, BingBot) через обратный DNS — они всегда проходят. Блокируются только те, кто маскируется под поисковик или ведёт себя как автоматизация. Опасны прямые блокировки по IP «всех ботов» без проверки rDNS — вот они действительно могут выбить сайт из индекса.
Чем отличается WAF от антибот-сервиса в защите от парсеров?
WAF (Web Application Firewall) фильтрует атаки на код — SQL-инъекции, XSS, попытки обхода аутентификации. Антибот фильтрует автоматизацию — клиентов, которые ведут себя как программы, а не как люди. Парсеры обычно не делают ничего «вредного» с точки зрения WAF: они ходят по страницам обычными GET-запросами. Поэтому WAF в одиночку не защитит от парсинга — нужен отдельный антибот-слой.
Как блокировать GPTBot и других AI-краулеров?
Самый простой способ — добавить их в robots.txt и в чёрный список User-Agent на уровне Nginx/WAF. Список актуальных AI-краулеров в 2026 году: GPTBot, ChatGPT-User, OAI-SearchBot, ClaudeBot, anthropic-ai, PerplexityBot, Google-Extended, Bytespider, Amazonbot, Applebot-Extended, FacebookBot. Подробный гайд с готовыми конфигами — в статье про защиту от AI-ботов.
Сколько стоит защита от парсеров для интернет-магазина?
Зависит от посещаемости и количества сайтов. Тарифы BotHunt стартуют от 890 ₽ в месяц за один сайт (Site), для группы из 5 проектов — 2 990 ₽ в месяц (Studio). Это в 5-15 раз дешевле, чем потери от утечки каталога конкурентам и от нагрузки на серверы. Все тарифы — в разделе с ценами.
Можно ли обнаружить парсера, который уже работает на сайте?
Да, и часто это делается за 10-20 минут анализа логов. Признаки в access.log Nginx: серии запросов с одного User-Agent с интервалом 0,1-1 секунда, 100% GET-запросы без POST, обход страниц по «лесенке» (товар 1, товар 2, товар 3 подряд), отсутствие запросов к статике (CSS/JS/картинки). Подробная инструкция с командами grep/awk — в нашей статье про обнаружение парсеров.
Помогает ли Cloudflare против парсеров после ухода из России?
Cloudflare продолжает работать, но в режиме без локальных PoP-узлов: задержки выросли, эффективность Bot Management для российских сайтов снизилась. Для проектов, ориентированных на РФ, рациональнее использовать локальные сервисы (BotHunt, Qrator, StormWall, NGENIX) — они работают через российскую инфраструктуру и не зависят от трансграничных каналов. Ссылки на официальные рекомендации Яндекса по работе с роботами есть в справке Яндекс Вебмастера.
Работает ли защита BotHunt на любой CMS?
Да. На WordPress установка идёт плагином из админки (1 клик, без правки кода). На Bitrix, Tilda, MODX, OpenCart, Joomla — через одну строку JavaScript в шаблоне сайта. На самописных движках (Django, Laravel, Node.js) — также через JS-агент, без модификации серверного кода. Дополнительно есть серверный режим (PHP-агент) — он добавляет TLS/JA3-фильтрацию на уровне запроса. Развёртывание занимает 1-5 минут.


