

Мы в BotHunt ежедневно обрабатываем трафик тысяч сайтов — и за последний год фиксируем устойчивый рост нового типа нежелательных гостей: AI-краулеров. GPTBot от OpenAI, ClaudeBot от Anthropic, PerplexityBot, Google-Extended — все они методично обходят страницы, извлекая текст и структуру данных для обучения языковых моделей. По данным Cloudflare Radar, трафик GPTBot с 2024 по 2025 год вырос на 305%, а доля AI-ботов уже составляет 4,2% всех HTML-запросов в сети.
Для большинства владельцев сайтов это незаметная угроза: сессии выглядят как обычный трафик, bounce rate не растёт, конверсии не падают. Но в фоне происходит две вещи: ваш контент используется без разрешения и без атрибуции, а сервер несёт дополнительную нагрузку — средний AI-бот делает от 100 до 2400 запросов в час к одному сайту. Это в 3–5 раз больше, чем обычный поисковый робот.
В этой статье разберём: какие AI-боты существуют, чем они отличаются от поисковых краулеров, почему robots.txt — не защита, и как настроить надёжную блокировку через Nginx, .htaccess, ASN-фильтрацию и поведенческий анализ. Отдельно поговорим о стандарте llms.txt — новом инструменте управления доступом для AI.
Какие AI-боты приходят на ваш сайт — и зачем
Все AI-краулеры делятся на два принципиально разных типа. Первый — обучающие боты (training crawlers): собирают данные для дообучения языковых моделей. Второй — поисковые боты (retrieval crawlers): нужны, чтобы AI-сервис мог цитировать ваш сайт в ответах и привлекать трафик обратно.
Это критически важное разделение, которое часто путают. Если вы заблокируете обучающий бот (GPTBot), но оставите поисковый бот (OAI-SearchBot) — вы защищаете контент и сохраняете возможность цитирования в ChatGPT. Если заблокируете всё — теряете обе возможности. Именно на этой путанице "сломались" сотни сайтов, поставивших в robots.txt агрессивный запрет на всё подряд.
Полная таблица AI-ботов: User-Agent и назначение
На середину 2026 года в индексе BotHunt насчитывается более 40 задокументированных AI-краулеров. Ключевые — в таблице ниже.
User-Agent | Компания | Тип | Блокировать? |
|---|---|---|---|
| OpenAI | Обучение модели | Да |
| OpenAI | ChatGPT-поиск / цитирование | Нет (если нужны цитаты) |
| OpenAI | Browsing (real-time) | Нет (поисковый) |
| Anthropic | Обучение модели | Да |
| Anthropic | Поиск / цитирование | Нет (если нужны цитаты) |
| Perplexity AI | Поиск + обучение | По ситуации* |
| Gemini обучение | На усмотрение | |
| Common Crawl | Открытый датасет | Да |
| ByteDance (TikTok) | Обучение / поиск | Да |
* Perplexity в 2025 году был пойман на обходе robots.txt: компания Cloudflare зафиксировала ротацию User-Agent и IP для обхода директив. Это делает его наиболее агрессивным среди публичных AI-краулеров.
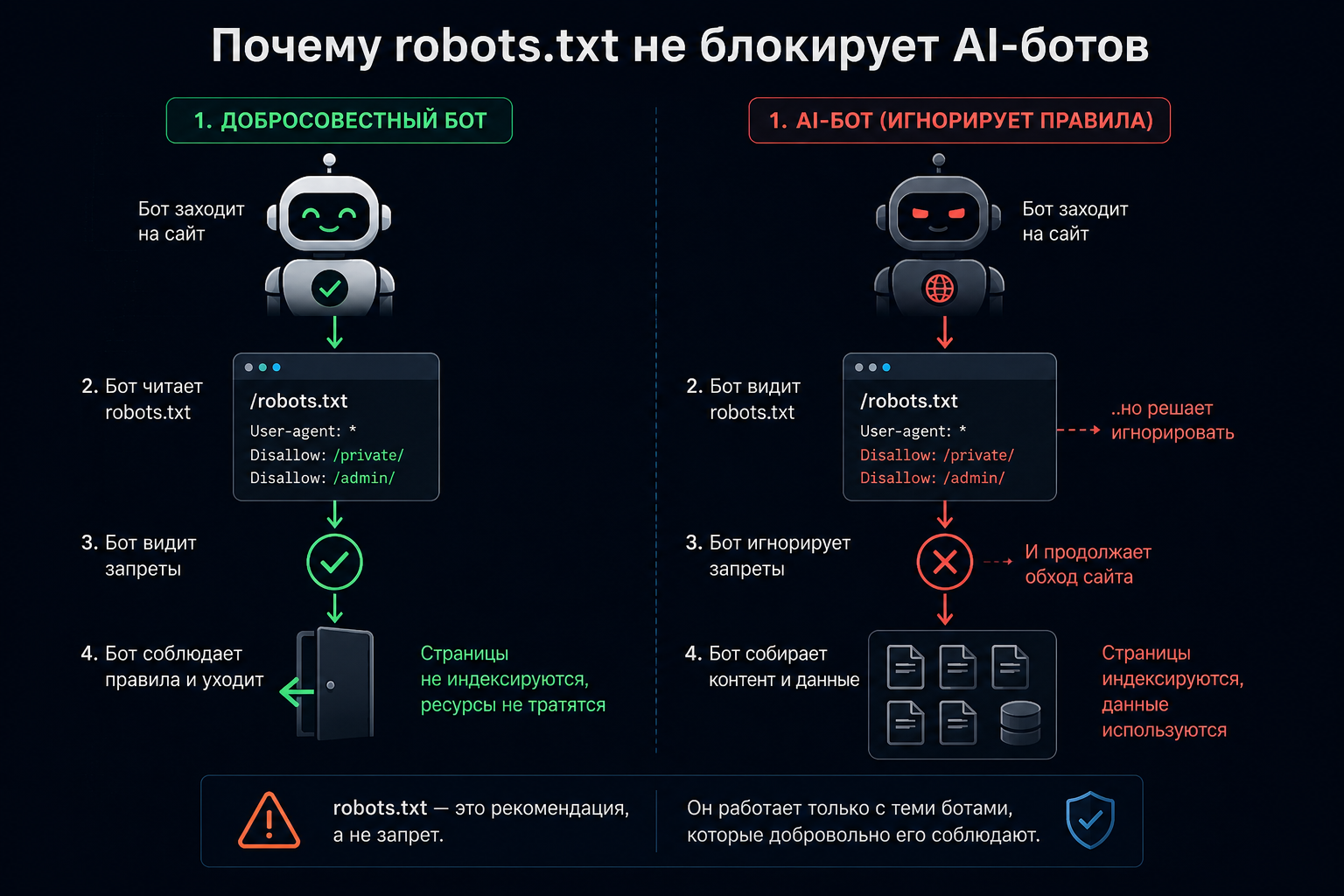
Почему robots.txt не защищает от AI-ботов
Robots.txt — это протокол вежливости, а не технический барьер. Он работает по принципу "добросовестного бота": краулер сам обязан проверить файл и соблюдать инструкции. Большинство крупных AI-компаний декларируют соблюдение robots.txt — но есть три структурные проблемы.
Недобросовестные игроки игнорируют его. Perplexity, Bytespider и сотни мелких AI-скрейперов просто не соблюдают robots.txt. По данным 2025 года, около 30% запросов от AI-ботов поступает без предварительной проверки robots.txt.
Спуфинг User-Agent. Бот может представиться как Chrome или Safari — robots.txt на него не распространится вообще. Для защиты от этого нужна верификация по IP, а не только по заголовку.
Нет гранулярного управления. Robots.txt не поддерживает логику "блокировать обучение, но разрешить поиск" на уровне одного User-Agent — вы либо разрешаете, либо закрываете всё для конкретного агента.
Мы в BotHunt видим это регулярно: сайт с корректным robots.txt продолжает получать AI-трафик, потому что часть агентов просто его не читает. По данным нашего мониторинга, у 43% сайтов с запретами в robots.txt AI-боты всё равно составляют более 1% реальных запросов.
BotHunt видит AI-трафик на поведенческом уровне — даже если бот меняет User-Agent. Попробовать бесплатно →
Как заблокировать AI-ботов через robots.txt: правильный шаблон 2026
Несмотря на ограничения, robots.txt — обязательный первый слой. Ключевой принцип: блокируйте обучающих краулеров и явно разрешайте поисковых — это сохранит видимость в ChatGPT и Claude без отдачи контента на обучение.
Блокировка обучающих AI-краулеров:
# Обучающие краулеры — блокируем
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: meta-externalagent
Disallow: /
User-agent: Applebot-Extended
Disallow: /Поисковые AI-боты — разрешаем для цитирования в AI-поиске:
# Поисковые боты — разрешаем
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /Важно: порядок правил в robots.txt имеет значение. Если вы используете глобальный User-agent: * с Disallow: /, поисковые AI-боты тоже попадут под запрет — если ниже не добавлен явный Allow для каждого из них.
Серверная блокировка: Nginx и Apache
Серверная блокировка принудительна — бот не может её обойти, просигнализировав о добросовестности. Это второй уровень защиты, необходимый для агентов, которые игнорируют robots.txt.
Nginx: блокировка по User-Agent
# В блоке server {} или location /
if ($http_user_agent ~* "(GPTBot|ClaudeBot|Google-Extended|CCBot|Bytespider|meta-externalagent|Applebot-Extended|Amazonbot)") {
return 403;
}Apache (.htaccess)
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|Google-Extended|CCBot|Bytespider) [NC]
RewriteRule .* - [F,L]
</IfModule>Ограничение этого подхода: бот может менять User-Agent и притворяться Chrome. В этом случае серверная блокировка по заголовку не сработает — нужна ASN-верификация.
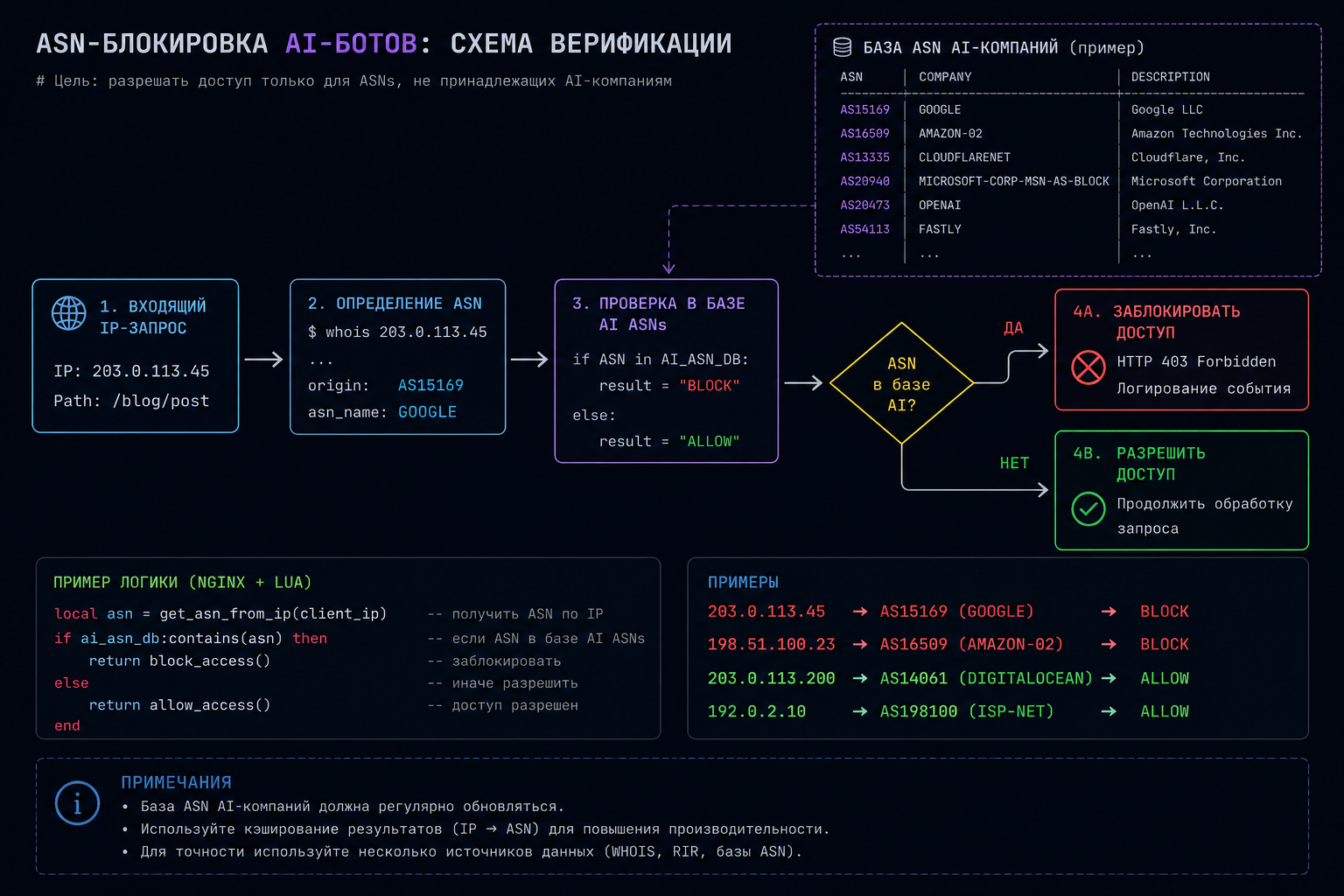
ASN-блокировка: надёжная защита от ai-ботов с подменой User-Agent
ASN (Autonomous System Number) — идентификатор сетевого блока, принадлежащего конкретной компании. OpenAI, Anthropic, Google публикуют списки своих IP-диапазонов в машиночитаемом JSON-формате. Верификация входящего IP по этим спискам — единственный способ надёжно идентифицировать краулер, даже если он меняет заголовки.
AI-компания | Источник IP-диапазонов | Основные ASN |
|---|---|---|
OpenAI | openai.com/gptbot-ranges.json | AS396982 (Google Cloud) |
Anthropic | anthropic.com/api/ips.json | AS14618 (Amazon AWS) |
Common Crawl | commoncrawl.org/faq | AWS, GCP диапазоны |
Perplexity AI | Официальный список отсутствует | Ротация провайдеров |
На практике для Nginx ASN-блокировка реализуется через модуль MaxMind GeoIP2 или динамически обновляемый список IP. Для WordPress-сайтов проще использовать специализированный сервис — вручную поддерживать актуальность IP-диапазонов, которые обновляются еженедельно, нереально.
BotHunt автоматически сверяет IP каждого посетителя с актуальными ASN-диапазонами AI-компаний — без ручной настройки. Подключить защиту →
llms.txt: управляемый доступ вместо полной блокировки
В 2025 году появился новый стандарт — llms.txt. По аналогии с robots.txt, это файл в корне сайта, который сообщает AI-агентам: что можно читать, что цитировать, а что закрыто. В отличие от robots.txt, llms.txt ориентирован именно на языковые модели и поддерживает структурированный markdown-формат.
Стандарт поддерживается поисковыми AI-агентами (Claude-SearchBot, OAI-SearchBot, PerplexityBot) — обучающие краулеры его пока игнорируют. Принятие невысокое: на середину 2026 года llms.txt размещён примерно у 10% доменов.
Минимальный пример llms.txt:
# llms.txt
> BotHunt — российский сервис защиты сайтов от ботов
## Разрешено для цитирования
- /blog
- /p/
- /
## Запрещено
- /admin
- /api
- /dashboard
## Контакт
info@bothunt.ruСтоит ли внедрять llms.txt прямо сейчас? Да — если вы хотите появляться в ответах ChatGPT и Claude. Нет — если это ваша единственная линия защиты от скрейпинга: llms.txt не имеет принудительного механизма исполнения. Подробнее читайте в статье «robots.txt для защиты от ботов: мифы и реальные возможности».
Матрица решений: что блокировать, что разрешать
Правильная стратегия зависит от типа сайта и бизнес-целей. Ориентируйтесь по таблице:
Тип сайта | GPTBot / ClaudeBot | OAI-SearchBot | Bytespider / CCBot |
|---|---|---|---|
Блог / медиа | Блокировать | Разрешить | Блокировать |
Интернет-магазин | Блокировать | Закрыть каталог | Блокировать |
SaaS / корпоративный | Блокировать | Разрешить | Блокировать |
Форумы / UGC | Блокировать | По ситуации | Блокировать |
Как BotHunt автоматически фильтрует AI-трафик
Ручная настройка блокировок — только первый уровень. Проблема в том, что списки User-Agent и IP-диапазонов обновляются постоянно: новые компании выходят на рынок, старые меняют инфраструктуру. Поддерживать актуальность самостоятельно — это 2–3 часа работы в неделю.
Агент BotHunt обрабатывает каждый запрос к сайту менее чем за 100 мс и применяет несколько слоёв проверок:
Сигнатурная проверка User-Agent — база содержит более 300 актуальных сигнатур AI-краулеров, обновляется еженедельно.
ASN-верификация — IP-адрес посетителя сверяется с актуальными диапазонами AI-компаний в реальном времени.
Поведенческий анализ — даже если бот замаскировался под человека, паттерны обхода страниц, частота запросов и браузерный fingerprint его выдают.
Гибкие правила — можно разрешить поисковые AI-боты и заблокировать только обучающие, без ручного редактирования robots.txt.
Для WordPress доступен готовый плагин — установка занимает 1 минуту. Для других CMS — один фрагмент PHP-кода в header. Подробнее о технологиях распознавания читайте в статье «Browser fingerprinting: как сервисы защиты опознают ботов».
AI-боты и SEO: как не навредить индексации Яндекса
Частая ошибка: владелец сайта ставит глобальный Disallow: / для User-agent: * и случайно блокирует не только AI-краулеры, но и Yandexbot, Googlebot. Или наоборот — пытается заблокировать только AI и нечаянно перекрывает Яндекс-поиск.
Никогда не используйте
User-agent: *для блокировки AI-ботов — только явные User-Agent строки.После изменений в robots.txt проверьте Яндекс Вебмастер → «Проверка robots.txt» и Google Search Console → «Инструмент проверки URL».
Через 24–48 часов убедитесь в логах, что Yandexbot и Googlebot продолжают краулинг в нормальном режиме.
Google-Extended блокирует использование в Gemini, но не влияет на обычную индексацию Google. Блокировка безопасна для SEO.
Чек-лист: полная защита от AI-ботов за 4 шага
robots.txt — добавьте запреты для GPTBot, ClaudeBot, CCBot, Bytespider. Явно разрешите OAI-SearchBot и Claude-SearchBot, если нужны цитирования в AI-поиске.
Серверная блокировка (Nginx/.htaccess) — принудительный 403 для ботов, которые игнорируют robots.txt. Обязателен для Bytespider и агрессивных скрейперов.
ASN-верификация — единственный способ поймать бота с поддельным User-Agent. Подключите сервис с автоматически обновляемыми IP-диапазонами.
Поведенческий анализ (BotHunt) — финальный слой для агентов, обходящих все предыдущие уровни. Работает in-line, менее чем 100 мс, без влияния на скорость сайта.
Если ваш сайт работает на WordPress — дополнительно изучите статью «Как защитить сайт от парсеров: 15 рабочих методов»: там разобраны rate-limiting и honeypot-техники, применимые и к AI-ботам.
Актуальный реестр User-Agent строк AI-краулеров поддерживается сообществом на robotstxt.com/ai — сверяйтесь с ним при обновлении правил блокировки.
Установите BotHunt за 1 минуту и получите автоматическую защиту от AI-краулеров, парсеров и поведенческих ботов — без ручных правок robots.txt и Nginx. Начать бесплатно →
Часто задаваемые вопросы
Что такое GPTBot и зачем он приходит на мой сайт?
GPTBot — официальный краулер OpenAI для обучения языковых моделей. Он обходит публичные страницы как Googlebot, но вместо индексации использует контент как обучающие данные. Владелец сайта не получает никакой атрибуции или трафика в ответ.
Нужно ли блокировать Claude-SearchBot и OAI-SearchBot?
Нет — если вы хотите цитироваться в ответах ChatGPT и Claude. Это поисковые агенты для citation в AI-поиске. Блокируйте только обучающие краулеры (ClaudeBot, GPTBot) — это принципиально разные боты.
Нарушает ли блокировка AI-ботов в robots.txt SEO-индексацию Яндекса?
Нет, если блокируете только конкретные User-Agent строки (GPTBot, ClaudeBot и т.д.). Yandexbot и Googlebot не входят в этот список. Главное — не использовать глобальный User-agent: * с Disallow: /.
Что делать, если AI-бот игнорирует robots.txt?
Перенести блокировку на уровень сервера (Nginx/Apache) или использовать антибот-сервис с ASN-верификацией. Robots.txt — рекомендация, а не барьер. Perplexity и Bytespider его игнорируют.
Влияет ли AI-трафик на скорость сайта?
Да. Средний AI-бот делает 100–2400 запросов в час — в 3–5 раз больше обычного поискового робота. У ряда клиентов BotHunt AI-трафик составлял до 15–20% серверных запросов до подключения блокировки.
Что такое llms.txt и нужен ли он мне?
llms.txt — файл в корне сайта, сообщающий AI-агентам, какой контент можно цитировать. Поддерживается Claude-SearchBot и OAI-SearchBot. Стоит внедрить для управления видимостью в AI-поиске, но от скрейпинга не защищает — обучающие краулеры его не соблюдают.
Можно ли монетизировать доступ AI-ботов к контенту?
В 2025–2026 годах крупные издания подписывают платные соглашения с OpenAI и Anthropic. Для среднего бизнеса прямая монетизация пока недоступна — но блокировка обучающего скрейпинга сохраняет переговорную позицию на случай стандарта лицензирования.
Как проверить, какие AI-боты посещают мой сайт?
Анализ логов Nginx: grep -i 'gptbot\|claudebot\|perplexitybot\|google-extended\|bytespider' /var/log/nginx/access.log. Либо используйте дашборд BotHunt — там AI-трафик отображается отдельной категорией с разбивкой по краулерам.


